개발 서버도 없던 팀이 GitOps를 갖추기까지: 맨땅에서 시작한 쿠버네티스 도입기
안녕하세요.
저는 프롭테크 플랫폼에서 백엔드 개발자로 근무 중인 3년차 백엔드 개발자 정정일입니다.
오늘은 저희 팀이 기존에 Docker 컨테이너 위에서 운영하던 Spring Cloud 기반 마이크로서비스(MSA)를 쿠버네티스(Kubernetes) 기반으로 전환하기 위해, 제가 제안하고 구축했던 과정을 공유해볼까 합니다.
이 과정에서 저희는 오랫동안 익숙하게 사용했던 Spring Cloud의 Eureka와 API Gateway를 덜어내고, GKE(Google Kubernetes Engine)와 ArgoCD를 도입했습니다.
제가 왜 이런 제안을 했고, 어떤 결정들을 내렸는지, 그 과정에서 어떤 현실적인 고민들이 있었는지, 그리고 무엇을 얻었는지 담아보려 합니다.
기존 아키텍처의 문제점
제가 3월에 팀에 합류한 저희 회사의 기존 MSA 아키텍처는 docker-compose나 셸 스크립트를 이용해 각 서비스를 도커 컨테이너로 실행하는, 초기에는 나름 잘 동작하는 구조였습니다. 하지만 서비스가 점점 많아지고 복잡해지면서, 피할 수 없는 ‘성장통’을 겪게 되었습니다.
크게 두 가지 문제가 저희를 괴롭혔습니다.
1. 단일 인스턴스의 한계
제가 입사한 시점의 저희 회사는 큰 인스턴스 하나에 모든 컨테이너를 올려서 운영했습니다. 회사 자금에 여유가 없는 상태였기 때문에 비용적인 측면에서는 유리한 선택이었습니다.
다만 레거시 모놀리스에서 MSA로 전환하는 과정을 진행하고 계셨고 그로 인해 서비스가 5개, 10개, 15개… 늘어나는 과정이었습니다. 문제는 이로 인해 나타나기 시작했습니다.
| |
서비스가 증가함에 따라 메모리가 부족해지면 일부 서비스가 OOM Kill이 일어나는 심각한 상황이 발생하기 시작했습니다.
CPU도 마찬가지였습니다. 특정 서비스가 CPU를 독점하면 다른 서비스들의 응답속도가 느려지는 ’noisy neighbor’ 문제가 발생하기도 했습니다.
더 큰 인스턴스로 스케일업? 그것도 한계가 있었고, 무엇보다 단일 장애점(SPOF) 이라는 근본적인 문제는 해결되지 않았습니다.
또한 MSA의 큰 장점 중 하나로 고가용성으로 꼽을 수 있을 것 같은데, 이런 단일 장애지점이 존재하는 환경에서의 배포는 MSA 아키텍처의 의미를 크게 퇴색시키지 않나 싶습니다.
2. 개발 환경의 부재
또 한 가지 팀에 합류하고 꼭 개선하고 싶었던 점은, 개발 서버의 부재였습니다. 모든 테스트를 로컬에서 하거나, 아니면… (끔찍하지만) 운영 환경에 조심스럽게 배포하면서 테스트했죠.
"이거 테스트 좀 해봐야 하는데..."
"로컬에서 전체 MSA 띄우면 노트북 터져요..."
"그럼... 운영에 조심히...?"이런 대화가 일상이었습니다.
이런 문제들을 겪으며 저희는 “더 이상 이렇게는 안 되겠다"는 결론에 이르렀고, 비즈니스의 연속성과 직결되는 확장성과 고가용성, 그리고 제대로 된 개발 환경을 확실히 잡기 위해 컨테이너 오케스트레이션의 표준인 쿠버네티스 도입을 제가 제안하게 되었고 팀원 분들과 협의를 거쳐 도입을 결정하게 되었습니다.
3. 어쩌다 보니 제가 하게 되었습니다
사실 저는 전문 DevOps 엔지니어가 아닙니다. 다만 전 직장에서 운 좋게(?) 인프라를 깊게 파보고 쿠버네티스를 운영해 볼 기회가 있었습니다.
전 직장에서 유일한 DevOps 담당자분이 퇴사하시게 되었는데, 후임자가 구해지지 않아 공백이 생길 뻔한 적이 있습니다. 그때 제가 담당자분을 찾아가 부탁드렸습니다.
“담당자님이 안 계시는 동안 혹시라도 서버에 문제가 생기면 누군가는 해결해야 할 텐데… 실례가 안 된다면 조금만이라도 알려주실 수 있을까요? 부족한 지식으로라도 어떻게든 버텨보겠습니다.”
당시 그런 저를 좋게 봐주셨는지 담당자분께서 1개월간 집중 멘토링 및 인수인계를 제게 해주셨고, 덕분에 쿠버네티스, AWS EKS, Jenkins, ArgoCD, ELK 등의 DevOps 및 인프라 관련 지식을 쌓을 수 있었습니다. 이후 7개월 정도 혼자 인프라를 운영을 했었거든요.
사실 1개월 멘토링으로 다 습득할 수 있는 양은 아니었기 때문에 던져주시는 인프라 관련 키워드를 노트에 다 받아적어 하나하나 찾아보며 공부했던 기억이 있네요… ㅎ..
지금 돌이켜보면 정말 무모한 도전이었지만… 덕분에 정말 많이 배울 수 있어 제 인생에 있어 하나의 큰 행운이였던 것 같습니다. 그 전까진 많은 회사에서 그렇겠지만 인프라 접근 권한 자체가 없었거든요.
새로 합류한 이번 팀도 상황은 비슷했습니다. 전문 DevOps 엔지니어가 따로 계시지 않았고, 백엔드 개발자들이 인프라 운영까지 겸하고 있었습니다.
마침 팀 내에서 쿠버네티스 실무 경험이 있는 사람이 저밖에 없다 보니, 자연스럽게(?) 제가 이번 마이그레이션 작업을 주도하게 되었습니다.
의사결정의 순간들
쿠버네티스를 도입하기로 마음먹고 나니, 두 가지 큰 갈림길에 섰습니다.
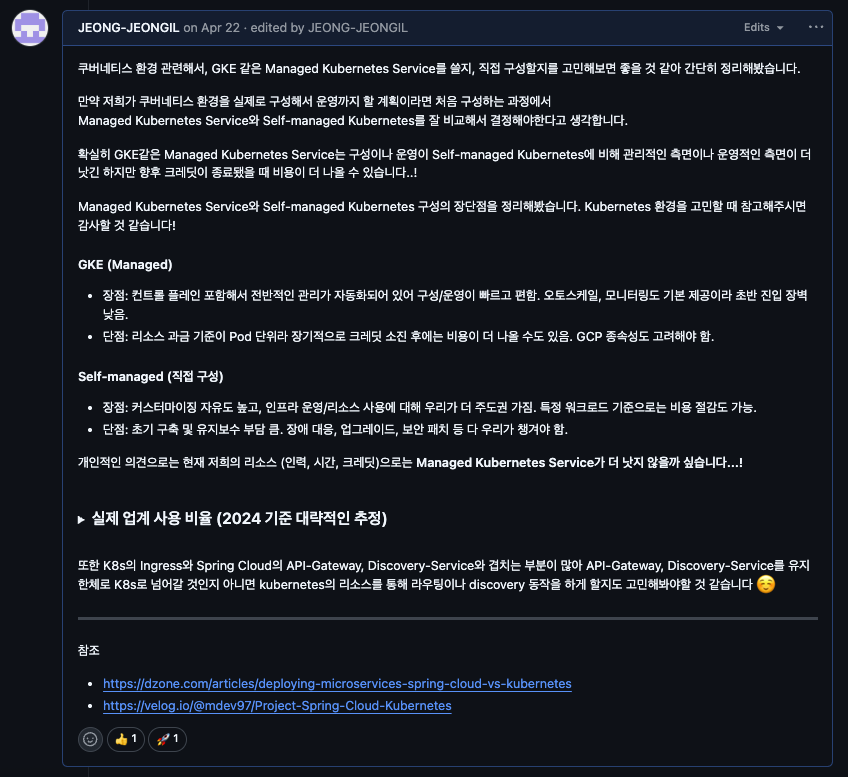
1. Managed vs Self-managed
첫 번째 선택은 “GKE 같은 관리형(Managed) 서비스를 쓸까, 아니면 우리가 직접 클러스터를 구축(Self-managed)할까?” 였습니다.
아마 쿠버네티스 도입을 고민하는 모든 팀이 거치는 과정일 겁니다. 저희 팀 역시 머리를 맞대고 각 방식의 장단점을 따져봤습니다.
| 구분 | Managed Kubernetes | Self-managed Kubernetes |
|---|---|---|
| 장점 | - 빠른 구축과 쉬운 운영: 컨트롤 플레인 관리를 GCP가 다 해주니 정말 편함 - 안정성 및 기본 기능: 오토스케일, 모니터링 등 필요한 기능이 바로 제공됨 - 낮은 진입 장벽: K8s 전문가가 아니어도 빠르게 시작 가능 | - 높은 자유도: 우리 마음대로 인프라를 주무를 수 있음 - 비용 최적화 가능성: 잘만 쓰면 비용을 아낄 수 있음 - 특정 클라우드에 묶이지 않음 |
| 단점 | - 비용: 장기적으로 크레딧이 끝나면 비용이 더 나올 수 있음 - 클라우드 종속성: 클라우드에 종속됨 | - 높은 초기/유지보수 비용: 구축, 업그레이드, 장애 대응… 전부 우리 몫 - 어려운 학습 곡선: 정말 잘 아는 전문가가 필요함 |
관련 글을 보면, 전체 K8s 사용자의 73%가 관리형 서비스를 사용한다고 해요. 그만큼 대부분의 팀이 속도와 안정성을 중요하게 생각한다는 뜻이겠죠.
결론적으로 저희 팀의 현재 인력과 시간을 고려했을 때, 초기 구축과 운영 부담이 적고 안정성이 보장되는 Managed Kubernetes가 현실적인 선택이었습니다. 일단 GKE로 쿠버네티스 운영 경험을 충분히 쌓고, 나중에 정말 필요해지면 그때 Self-managed로 넘어가도 늦지 않다고 판단했습니다.
2. Spring Cloud를 버리기로 한 결정
두 번째 선택은 “Spring Cloud의 Eureka와 API Gateway, 계속 안고 가야 할까?” 였습니다. 단순히 인프라만 옮기는 게 아니라, 특정 프레임워크에 대한 종속성을 끊어낼 기회라고 생각했거든요.
물론 Spring Cloud Kubernetes라는 좋은 프로젝트가 있어서, 기존 코드를 거의 그대로 쓰면서 쿠버네티스와 통합할 수도 있었습니다. 하지만 이 방식은 여전히 우리 아키텍처를 Spring, 더 나아가 JVM 생태계에 묶어두는 것이나 다름없다고 생각했습니다.
저희 회사는 AI 모델을 활용하는 등 Java/Spring 외에 Python 같은 다른 언어로 만든 서비스의 중요성이 점점 커지고 있었습니다. 미래에 다양한 기술 스택의 서비스들을 아무 문제 없이 통합하고 확장하려면, 특정 언어에 얽매이지 않는(Language-Agnostic) 아키텍처가 필요했습니다.
그래서 저희는 과감한 결정을 내렸습니다.
- 프레임워크 종속성 탈피: Spring Cloud 의존성을 걷어내자. 어떤 언어로 만든 서비스든 쿠버네티스 안에서 동등하게 대우받을 수 있도록
- 쿠버네티스 네이티브 기능 활용: Eureka의 역할은 쿠버네티스의
K8s DNS + Service가, API Gateway의 역할은Ingress가 충분히 해줄 수 있다. 기술 스택을 단순화하고 중복을 없애자. - 미래를 위한 확장성 확보: 나중에 Python 기반 AI 서비스가 들어오든, 어떤 새로운 서비스가 생기든, 쿠버네티스 표준 방식으로 매끄럽게 통합하자.
결론적으로 저희는 Eureka와 API Gateway를 제거하고, 쿠버네티스의 Service와 Ingress를 사용하기로 결정했습니다.
아키텍처 전환 작업
처음에는 Eureka와 API Gateway를 제거하고 Service와 Ingress를 도입하는 과정이 비교적 스무스하게 넘어갈 수 있을 거라 생각했습니다. 하지만 서비스 간에 Eureka를 통해 서로를 바라보는 Endpoint가 수정되어야 한다는 점에서 코드도 변경되어야 하는 부분이 있었습니다.
A. 코드 레벨 변경
멀티모듈로 통합
기존에는 MSA의 각 서비스들을 개별 레포에 관리하고 있었거든요.
# 기존 레포 구조
- user-service/
- order-service/
- payment-service/
- notification-service/
- agent-service/
... (10개가 넘는 개별 레포)Feign Client URL 하나 바꾸려면 16개 레포를 일일이 수정하고, Commit하고, PR 올리고… 더 큰 문제는 공통 코드가 각 프로젝트마다 복사되어 있었다는 점입니다. 또 공통적인 설정인 모니터링 관련해서도 프로젝트별로 설정이 제각각이라 관리 부담이 컸습니다.
| |
저희 팀의 인력이 여유로운 상태는 아니었기 때문에, 별도로 관리하는 리소스를 줄이고자 프로젝트를 멀티모듈 형식으로 통합하기로 결정했습니다.
# 새로운 멀티모듈 구조
multi-module-backend/
├── common/ # 공통 모듈
│ ├── feign-clients/ # 모든 Feign Client 모음
│ ├── dto/
│ └── utils/
├── user-service/
├── notification-service/
├── match-service/
└── ...COMMON 모듈을 도입해서 Feign Client들을 한 곳으로 모으니, 수십 개 서비스의 Feign Client를 한 번에 수정할 수 있게 되었습니다.
( 멀티모듈로 전환하는 과정은 차후 다른 글에서 자세히 다루도록 하겠습니다. )
B. 인프라 레벨 변경
1. Eureka → K8s Service/DNS
기존에 Eureka Server가 하던 서비스 디스커버리 역할을 이제 쿠버네티스의 Service와 DNS가 대신하게 했습니다.
| |
이제 user-service-svc라는 이름으로 클러스터 내 어디서든 접근 가능합니다. Eureka Server 운영 부담도 사라졌죠.
2. API Gateway → Ingress
기존 Spring Cloud Gateway 대신 쿠버네티스 Ingress를 사용합니다.
| |
이제 외부 트래픽은 Ingress가 받아서 적절한 서비스로 라우팅해줍니다.
3. GitOps with ArgoCD
인프라 구성과 애플리케이션 배포는 ArgoCD를 이용한 GitOps 방식으로 완전히 바꿨습니다. 쉽게 말해, 모든 인프라 설정을 Git 리포지토리(manifest-ops)에서 코드로 관리하는 겁니다.
저희 리포지토리 구조는 대략 이렇습니다.
| |
제가 구축한 CI/CD 파이프라인은 다음과 같습니다.
- 개발자가 코드를 수정하고 PR이 Merge되면 자동으로
deployment.yaml의 이미지 태그만 바꿉니다. (저희는 이 부분을 Github Actions로 구축했습니다.) - 이미지 태그가 변경되면 ArgoCD가 “어, 변경 사항이 있네?” 하고 감지합니다.
- 개발 환경은 자동으로 Sync하도록 구성
- 운영 환경은 안정성을 위해 개발자가 직접 Sync하도록 구성
- 이후 Git에 정의된 대로 클러스터의 상태를 자동으로 맞춰줍니다.
이 구조 덕분에 더 이상 제가 직접 kubectl apply 같은 명령어를 직접 칠 필요가 없어졌습니다.
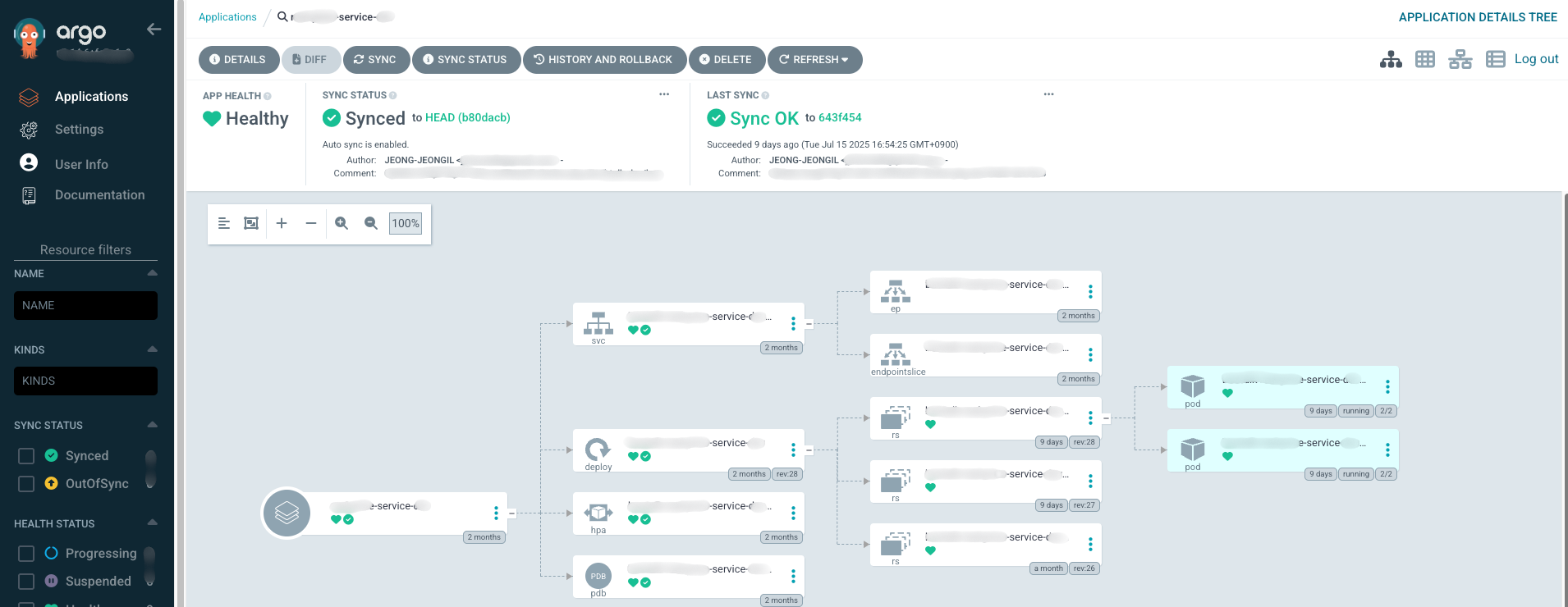
이제 모든 변경 이력이 Git에 남아서 누가, 언제, 왜 바꿨는지 명확하게 추적할 수 있고, 문제가 생기면 이전 버전으로 돌아가는 것도 훨씬 쉬워졌습니다.
C. 관측성(Observability) 개선
Spring Cloud 환경에서는 Prometheus가 Eureka를 통해 서비스를 발견하고 메트릭을 수집하도록 구성했었습니다. 하지만 Eureka를 제거하면서 모니터링 구조도 완전히 재설계해야 했습니다.
1. Prometheus: Pull에서 Push로의 전환
기존에는 Prometheus가 Eureka를 통해 서비스를 발견하고 메트릭을 긁어가도록 설정해뒀었습니다.
| |
쿠버네티스로 전환하면서 이 구조를 완전히 뒤집었습니다. OpenTelemetry를 통한 Push 방식으로요.
새로운 방식에서는 각 서비스가 OpenTelemetry Collector 사이드카로 메트릭을 보내고, Collector가 다시 Prometheus로 전달하는 구조입니다.
| |
이제 각 서비스는 자신의 메트릭을 능동적으로 OpenTelemetry Collector(localhost:4317)로 보내고, Collector가 Prometheus Remote Write API를 통해 중앙 Prometheus 서버로 전달합니다.
[Spring Boot App]
↓ (OTLP/gRPC)
[OTel Collector Sidecar]
↓ (Prometheus Remote Write)
[Prometheus Server]이 전환이 쉽지는 않았습니다… 기존 Grafana 대시보드를 전부 다시 만들어야 했고, 메트릭 이름도 다 바뀌어서 알람 규칙도 새로 짜야 했습니다. 하지만 결과적으로 각 서비스가 자신의 메트릭을 능동적으로 보내는 더 확장 가능한 구조가 되었죠.
2. 사이드카 패턴으로 모니터링 통합
앞서 저희의 문제점 중 하나로 “서비스마다 모니터링 설정이 제각각이라 관리 부담이 크다” 는 점을 언급했습니다. 이 문제를 해결하기 위해, 저는 각 애플리케이션 Pod에 OpenTelemetry Collector를 ‘사이드카’ 컨테이너로 함께 배포하는 방식을 택했습니다. 말로만 하면 감이 잘 안 오니, 저희 설정 예시를 보여드리겠습니다.
| |
구조를 간단히 설명드리면 이렇습니다.
- 메인 애플리케이션 컨테이너는
JAVA_TOOL_OPTIONS환경변수를 통해 Java Agent를 실행시켜서 로그, 트레이스, 메트릭 데이터를 수집합니다. - 바로 옆에 붙어있는
otel-collector사이드카 컨테이너가 이 데이터들을 대신 받아줍니다. - 사이드카는 미리 약속된 설정(
otel-collector-config)에 따라 수집한 데이터를 Loki, Tempo, Prometheus 같은 곳으로 보내주는 역할을 합니다.
이 구조 덕분에, 저희는 애플리케이션 코드 한 줄 건드리지 않고 모든 서비스에 일관된 관측 가능성 기능을 붙일 수 있었습니다. 제각각이던 설정을 한 곳에서 관리하게 된 거죠.
3. Grafana로 모든 것을 한눈에
이렇게 중앙화된 파이프라인을 통해 Loki, Tempo, Prometheus로 모인 모든 데이터는 최종적으로 Grafana 대시보드에서 통합되어 시각화됩니다.
이제 저희 팀은 Grafana 화면 하나만으로 모든 서비스의 상태를 한눈에 파악하고, 장애가 발생하면 로그와 트레이스를 넘나들며 신속하게 원인을 분석할 수 있게 되었습니다. 제각각이던 모니터링 설정이 하나로 통합되면서 얻게 된 가장 큰 선물이었습니다.
개발 환경 구축: 쿠버네티스 검증을 겸한 전략적 선택
쿠버네티스 도입 과정에서 저희가 내린 중요한 결정 중 하나는 운영 환경보다 개발 환경을 먼저 구축하는 것이었습니다.
앞서 언급했듯이 개발 환경의 필요성은 이미 절실했습니다. 하지만 단순히 개발 환경이 필요해서만은 아니었습니다. 쿠버네티스라는 새로운 환경을 검증하고, 문제를 안전하게 발견하고 해결할 수 있는 샌드박스가 필요했던 거죠.
그래서 저는 다음과 같은 전략으로 접근했습니다:
- 개발 환경을 먼저 쿠버네티스로 구축 - 운영 환경에 영향 없이 안전하게 시행착오를 겪을 수 있는 환경
- 프론트엔드 팀에 협조 요청 - 웹과 앱 팀에 개발/로컬 환경에서는 새로 구축한 쿠버네티스 개발 서버의 Endpoint를 호출하도록 요청
- 충분한 검증 후 운영 전환 - 개발 환경에서 안정성이 확인되면 그때 운영 환경을 이관
이 접근법 덕분에 개발자들은 로컬에서 노트북을 터뜨리지 않고도, 그리고 운영 환경에 “조심스럽게” 배포하지 않고도 안전하게 테스트할 수 있게 되었습니다.
물론 이 과정이 절대 쉬운 일은 아니었습니다… 환경 변수로 분리되지 않고 하드코딩되어 있는 설정들도 있었어서 운영환경에서 AWS SQS에 발행된 이벤트를 개발 서버가 컨슘해버리는 일도 있었죠 😢 (이 사건은 뒤에서 자세히 다룹니다)
트러블슈팅: 고통스러웠던 순간들
1. 개발 환경이 운영 SQS를 컨슘해버리는 문제
개발 환경을 처음 구축하면서 발생한 가장 아찔했던 사고를 빼놓을 수 없을 것 같습니다.
기존에는 개발 서버가 아예 없어서 모든 서비스가 운영 환경 하나만 바라보고 있었습니다. 그런데 코드를 살펴보니…
| |
네, SQS URL이 코드에 하드코딩되어 있었던 겁니다. 개발 환경이 없었으니 당연히 환경별 분리 같은 건 고려가 안 되어 있었죠.
개발 클러스터를 띄우고 나서 벌어진 일은 예상하신 그대로입니다.
“어? 왜 운영에서 통계 데이터가 이상하죠?”
개발 환경이 운영 AWS SQS의 이벤트를 간헐적으로 컨슘해버린 것입니다. 😭 하드코딩된 URL 때문에 개발 환경도 똑같이 운영 큐를 바라보고 있었던 거죠.
긴급하게 개발 환경을 내리고, 코드를 수정했습니다. 또 개발서버가 컨슘해버린 이벤트들을 개별적으로 발행해줘야 했죠 🥲
| |
이 사건으로 깨달은 교훈:
- 하드코딩은 시한폭탄이다
- 개발 환경이 없던 시스템에 개발 환경을 추가할 때는 모든 외부 연동 포인트를 점검해야 한다
- “일단 돌아가게만 만들자"는 마인드가 나중에 얼마나 큰 빚이 되는지…
지금은 모든 환경 설정을 코드에서 분리하고, 환경별로 철저히 격리했습니다. 다시는 이런 일이 없기를…
2. 예상치 못한 네트워크 이슈: 사라진 외부 API 연동
쿠버네티스 전환 중 당황스러웠던 순간 중 하나는 외부 API가 갑자기 동작하지 않았을 때였습니다.
개발 환경에서 테스트하던 중이었습니다.
Connection timeout...
Connection timeout...
Connection timeout...외부 파트너사의 API가 타임아웃을 뱉으며 계속 실패했습니다. 이상한 점은 기존 인스턴스의 Docker 환경에서는 정상 동작한다는 거였습니다.
“설정이 잘못됐나? DNS 문제인가?”
코드도 같고, 설정도 같은데 왜 쿠버네티스에서만 안 되는 걸까요? 아마 많은 분들이 어렵지 않게 원인을 추측하실 수 있을 것 같습니다.
원인 파악: 문서화되지 않은 방화벽 설정
문득 “혹시 방화벽?“이라는 생각이 들었습니다. 외부 파트너사에 조심스럽게 문의를 드렸죠.
“혹시 저희가 이용중인 서비스에 방화벽을 관리하고 계신지 확인 가능할까요?”
답변은 예상대로였습니다. 파트너사에서 우리 서버의 IP를 방화벽 whitelist에 등록해두고 있었던 겁니다.
문제는 이 사실을 아는 사람이 팀에 아무도 없었다는 점이었습니다. 3월에 합류한 저는 물론이고, 기존 팀원분들도 모르고 계셨어요. 레거시 시스템을 구축했던 분들은 이미 퇴사한 상태였고, 문서는 어디에도 없었습니다. 😢
해결책: Cloud NAT로 고정 IP 확보
이제 원인은 알았는데, 해결이 문제였습니다.
GKE는 노드를 오토스케일링하면서 IP가 동적으로 변합니다. 특정 노드 IP를 방화벽에 등록하는 방식으로는 근본적인 해결이 불가능했죠.
고민 끝에 Google Cloud NAT를 도입하기로 했습니다.
[GKE Pods] → [Cloud NAT] → [고정 IP] → [외부 API]Cloud NAT를 구성해서 모든 노드의 Egress 트래픽이 고정된 IP 하나로 나가도록 설정했습니다.
| |
이 고정 IP를 파트너사에 전달하고 방화벽에 등록한 후에야 정상적으로 API 호출이 가능해졌습니다.
이 사건을 통해 배운 교훈:
- 문서화는 선택이 아니라 필수다 - 특히 외부 연동 관련 설정은 반드시 기록해야 한다
- 인프라 전환 시 외부 의존성 체크리스트가 필요하다 - DB, 캐시만이 아니라 방화벽, VPN 등도 포함
- 레거시 시스템에는 숨겨진 지뢰가 있다 - 충분한 시간을 두고 검증해야 한다
그래서, 무엇이 달라졌을까?
Docker-compose에서 쿠버네티스 환경으로의 전환은 저희 팀에 정말 많은 긍정적인 변화를 가져왔습니다.
- 운영이 편해졌어요: 배포 자동화, 오토스케일링, 심지어 서비스가 죽으면 알아서 살려주는 자가 치유(Self-healing) 기능까지, 운영 부담이 정말 많이 줄었습니다.
- 개발자는 개발에만 집중: 개발자들은 더 이상 인프라를 신경 쓰지 않고 비즈니스 로직 개발에만 집중할 수 있게 되었습니다. 물론 저는 쿠버네티스 인프라까지 신경 써야 하긴 하지만요 ㅎㅎ..
- Rollback의 간편화: ArgoCD는 ReplicaSet을 이용한 Rollback을 지원하기 때문에 특정 버전을 배포했을 때 문제가 있다면 기존에 개발자가 직접 하나하나 처리해줘야 했던 Rollback을 간단하게 할 수 있었습니다. 물론 Rollback할 일이 없는 게 가장 베스트겠지만요 ㅎ..
노드들에 잘 떠있는 파드들을 보고만 있어도 뿌듯해집니다.. 그 전에는 제 개인적으로 공부하고자 쿠버네티스 클러스터를 구성해본 적은 있지만 제 손으로 직접 회사 서비스를 운영 중에 무중단으로 쿠버네티스 환경으로 이관에 성공하고 구축했다는 게 엄청 큰 만족감을 주더라고요 😊
비용, 그 현실적인 이야기
개발 블로그에서 잘 다뤄지지 않지만 누구나 궁금한 질문, “그래서 비용은 얼마나 나왔나요?”
솔직히 말씀드리면, 쿠버네티스 전환 후 인프라 비용이 약 2.5~3배 정도 증가했습니다.
비용이 증가한 이유
- GKE 관리 비용 - Managed Kubernetes의 컨트롤 플레인 비용
- 개발 환경 신규 구축 - 기존에 없던 완전한 개발 클러스터 추가
- 고가용성을 위한 리소스 - 노드 여러 개, 로드밸런서, Cloud NAT 등
하지만 저희는 GCP 스타트업 프로그램을 활용해 1년간 충분한 크레딧을 확보한 상태였습니다.
“어차피 1년 안에 다 못 쓸 크레딧인데, 제대로 된 인프라 만들어보자!”
이런 전략적 판단으로 접근할 수 있었습니다. 크레딧이 끝나는 시점에는 다음과 같은 계획을 세우고 있습니다:
- 불필요한 리소스 정리 및 Right-sizing
- 개발 환경은 업무 시간에만 가동 (야간/주말 자동 중지)
- Spot Instance 활용 검토
그럼에도 충분한 가치가 있었던 이유
비용만 보면 2배 이상 증가했지만, 얻은 것은 훨씬 많지 않았나 싶습니다.
- 개발자 생산성 향상 - “운영에 조심히 배포"하던 시절과는 차원이 다릅니다
- 장애 대응 시간 단축 - 통합 모니터링으로 MTTR(평균 복구 시간) 대폭 감소
- 운영 부담 감소 - 자동화로 야근과 주말 대응이 줄었습니다
- 비즈니스 안정성 - 더 이상 “서비스 하나 죽으면 전체 장애” 걱정 없음
시스템이 안정적으로 돌아가 사용자 신뢰도가 하락되는 일을 방지한 것만으로도 비용, 그 이상의 가치를 만들어낸다고 생각합니다. 불안정한 시스템으로 인한 안좋은 사용자 경험은 서비스 이탈을 야기하니까요.
마치며
Docker-compose에서 쿠버네티스로의 전환은 단순히 기술 스택을 바꾸는 것을 넘어, 저희 팀의 개발과 운영 문화를 한 단계 성장시키는 계기가 되었습니다. 선언적 인프라 관리와 GitOps 문화를 통해 팀 전체의 생산성과 시스템 안정성을 모두 잡을 수 있었으니까요.
물론, 쿠버네티스의 방대한 학습 곡선이나 복잡한 네트워킹 등 아직 배워나가야 할 것들이 많다고 생각합니다. 하지만 이번 전환을 통해 얻은 경험은 앞으로 마주할 기술적 도전에도 맞설 수 있는 든든한 자산이 될 것이라 생각합니다.
이 글이 저희와 비슷한 고민을 하고 있는 다른 개발자분들께 작은 도움이 되기를 바라며, 이만 글을 마치겠습니다. 긴 글 읽어주셔서 감사합니다.