서비스 장애는 사용자가 알려주지 않아도 알아야한다 - 사내 모니터링 시스템 구축기
안녕하세요.
프롭테크 플랫폼에서 백엔드 개발자로 근무 중인 3년차 백엔드 개발자 정정일입니다.
올해 3월에 팀에 합류한 후, 눈에 띈 것 중 한가지는 팀에서 모니터링 시스템에 개선할만한 부분들이 보였다는 것이었습니다.
기존에는 AWS CloudWatch를 이용하고 있었지만 효과적으로 활용되지 않고 있다는 점이 존재했습니다.
특히 장애가 발생하더라도 사용자 문의를 통해서만 문제를 인식할 수 있었고, 문제 발생부터 개발팀의 인식까지 시간이 오래 걸리는 상황이 반복되면서 더 효과적인 모니터링 시스템의 필요성을 절실히 느꼈습니다.
이 글에서는 제가 왜 새로운 모니터링 시스템이 필요하다고 느꼈는지, 그리고 어떻게 구축했는지 공유하려고 합니다.
문제 상황: 사용자가 알려줘야 알 수 있었던 장애
팀에 합류했을 때, 서비스 장애 감지 프로세스는 다음과 같았습니다.
문제 발생 → 사용자 CS 접수 → 문제 인식 → 원인 파악 → 해결이 프로세스의 가장 큰 문제점은 사용자가 불편함을 겪고 직접 CS를 통해 알려줘야만 문제를 인식할 수 있다는 점이었습니다. 하지만 실제로 CS로 문의하는 사용자는 전체 문제 경험자의 극히 일부에 불과합니다.
이와 관련된 부분은 네이밍 컨벤션의 부재는 장애로 이어진다에서도 한번 다룬 적이 있지만 제가 굉장히 중요하게 생각하는 부분이기 때문에 한번 더 언급하도록 하겠습니다.
여러분은 흔히 앱을 사용하시다 이상한 문구가 뜨며 내가 원하는 기능이 동작하지 않을 때 어떻게 하시나요? 고객센터로 연락해서 설명하는 경우가 많으신가요? 아니면 “에잇!!” 하며 앱을 꺼버리는 경우가 많으신가요?
정말 필요한 기능이거나 많이 화나시지 않는 경우 대부분 유저분들은 앱을 그냥 꺼버리거나 하는 경우가 많으실 겁니다. 이처럼 사용자가 예기치 못한 상황을 맞닥뜨리더라도 회사 내부적으로 파악하기는 모니터링 시스템 없이는 어려울 겁니다.
이는 사용자 이탈이라는 비즈니스적으로 치명적인 결과를 야기할 수 있기 때문에 아주 큰 문제가 될 수 있습니다.
유저분들의 대략적인 CS 유입 확률입니다. 이 수치들은 직접적인 통계 자료라기보다는 광범위한 고객 행동 연구를 바탕으로 한 경험적 추정치임을 참고해 주세요.
| 요인 (Factor) | 설명 (Explanation) | 추정 유입 확률 (Estimated Inflow Probability) | 주요 출처 및 근거 (Key Sources & Rationale) |
|---|---|---|---|
| 사용자 이탈 경향 | 서비스 성능 저하(로딩 지연, 오류) 시 사용자의 인내심이 매우 낮으며, 문제 해결 시도보다 즉각적인 이탈을 선호합니다. | 5% 미만 | Think with Google: 모바일 페이지 로딩 시간이 1초에서 3초로 늘어나면 이탈률이 32% 증가하며, 1초에서 5초로 늘어나면 90% 증가합니다. 이는 사용자가 문제에 직면했을 때 빠르게 이탈하는 경향을 보여줍니다. (Find out how you stack up to new industry benchmarks for mobile page speed) |
| 불만족 고객의 침묵 | 불만족한 고객은 불평하기보다 조용히 서비스를 떠나는 경향이 강하며, 고객센터 문의는 추가적인 노력과 시간을 요구합니다. | 5% ~ 10% | Qualtrics: 고객의 96%는 나쁜 경험을 했을 때 불평하지 않고 단순히 떠난다고 합니다. 이는 장애를 겪은 사용자가 고객센터로 문의하기보다 이탈할 확률이 높다는 것을 시사합니다. (Customer Loyalty: What it is and how to build it) |
| 장애의 심각성 및 반복성 | 치명적이고 반복적인 장애일수록 사용자가 문제 해결을 위해 고객센터에 연락할 가능성이 높아집니다. | 5% ~ 20% (심각한 경우) | 간접 추정: 특정 연구보다는 전반적인 고객 서비스 및 사용자 경험(UX) 전문가들의 일반적인 견해를 바탕으로 합니다. 심각한 금전적 손실이나 서비스 이용 불능 상태는 고객의 문의 유발 가능성을 높입니다. |
| 고객센터 접근성 | 문의 채널의 복잡성(ARS, 긴 대기시간)은 사용자에게 또 다른 장벽으로 작용합니다. 반대로, 쉽고 빠른 해결이 가능한 경우 유입이 증가할 수 있습니다. | 접근성 낮을 시 1% 미만 접근성 높을 시 10% 이상 (최대) | 간접 추정: 고객 경험(CX) 및 콜센터 관리 분야의 통계와 원칙에 기반합니다. 고객센터 응답 시간, 채널 다양성(챗봇, FAQ, 실시간 채팅 등)이 고객 만족도 및 문의율에 직접적인 영향을 미칩니다. (예: Zendesk, Genesys 등의 고객 서비스 리포트에서 관련 내용 확인 가능) |
| 사용자 관계/충성도 | 서비스에 대한 충성도가 높거나, 필수적인 서비스로 인식하는 경우 사용자는 문제를 해결하기 위해 적극적으로 노력할 수 있습니다. | 10% ~ 25% (충성 고객의 경우) | 간접 추정: 고객 관계 관리(CRM) 및 고객 충성도 연구에서 나타나는 경향입니다. 충성 고객은 문제 해결에 더 많은 인내심을 보이고, 서비스 개선을 위한 피드백을 제공하려는 의지가 강합니다. (예: Bain & Company의 NPS(Net Promoter Score) 관련 연구 등) |
이처럼 사용자분들이 CS를 통해 유입해주시는 경우는 사용자 경험에 비해 굉장히 드물기 때문에 저희는 사용자분들이 맞이한 장애를 CS 유입 없이 탐지할 필요가 있다고 생각합니다.
기존 CloudWatch의 한계와 낮은 활용도
기존에는 AWS CloudWatch를 사용하고 있었지만, 다음과 같은 한계로 인해 활용도가 낮았습니다.
- 비용 효율성 문제: CloudWatch는 로그 양이 증가할수록 비용이 급격히 증가하는 구조. 따라서 충분히 탄탄하고 다양한 로그를 쌓기가 부담스러웠습니다.
- 검색 기능의 한계: 복잡한 쿼리나 상관관계 분석이 어려움
- 통합 관측성 부재: 로그, 메트릭, 트레이스를 통합적으로 보기 어려움
- 알림 시스템 구성의 복잡성: 세밀한 알림 규칙 설정이 번거로움
- 커스터마이징 제한: 대시보드나 시각화 도구의 유연성 부족
이러한 한계로 인해 CloudWatch는 주로 기본적인 로그 저장 용도로만 사용되었고, 실질적인 모니터링과 알림 시스템으로는 제대로 기능하지 못했습니다. 이러한 문제를 해결하기 위해, 오픈소스 기반의 새로운 로깅 및 모니터링 시스템을 구축하기로 결정했습니다.
새로운 모니터링 시스템 아키텍처
새로운 모니터링 시스템은 다음과 같은 컴포넌트로 구성했습니다.
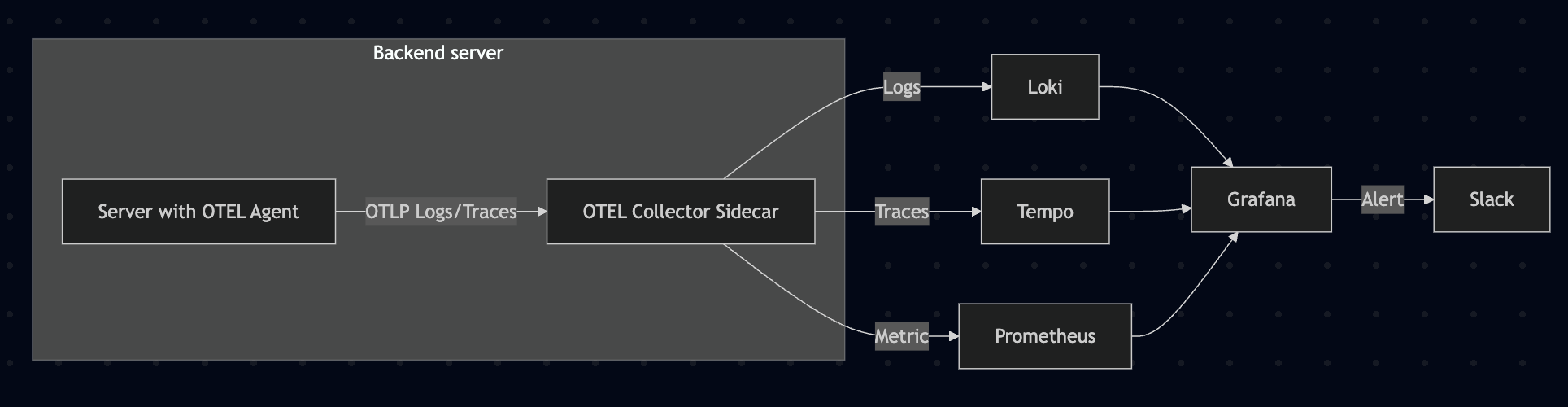
- OpenTelemetry: 애플리케이션 계측 및 텔레메트리 데이터 수집
- Java Agent: 애플리케이션 코드 변경 없이 자동 계측
- Collector: 데이터 수집, 처리, 내보내기 담당
- Loki: 로그 집계 및 저장 (ELK Stack의 Elasticsearch + Logstash 대체)
- Prometheus: 메트릭 수집 및 저장
- Tempo: 분산 트레이싱 (APM)
- Grafana: 통합 대시보드 및 알림 시스템
처음에 시스템 구축 과정에서 ELK Stack와 Loki, Grafana, Tempo, Prometheus 스택 사이에 고민을 많이 했습니다.

팀 내에서 회의도 여러 차례 진행하며 논의도 많이 진행했습니다.
이 스택을 선택한 주요 이유는 다음과 같습니다.
- 비용 효율성: ELK Stack에 비해 Loki는 인덱싱 방식이 다르고 리소스 사용량이 적어 비용 효율적
- 통합 관측성: Grafana를 통해 로그(Loki), 메트릭(Prometheus), 트레이스(Tempo)를 한 곳에서 확인 가능
- 확장성: 쿠버네티스 환경에 최적화된 구성으로 서비스 확장에 유연하게 대응
- 커뮤니티 지원: 활발한 오픈소스 커뮤니티와 풍부한 레퍼런스
등등의 이유가 있는데 솔직하게 말씀드리면 Loki, Grafana, Tempo, Prometheus 스택으로 선택한 가장 큰 이유는 비용 문제였습니다.
아무래도 ELK Stack에 비해 가볍다 보니 Cloud에서 운영한다고 했었을 때 ELK Stack에 비해 스펙을 더 낮게 측정하고 운영이 가능했고 저희 회사가 자금에 여유가 있는 상태는 아니었기 때문에 비용적으로 더 유리한 스택을 고른 것입니다.
ELK Stack vs Grafana + Loki 비용 예상 비교표
| 항목 | 구성 요소 | 최소 사양 | 권장 사양 | EC2 인스턴스 유형 (서울) | 시간당 요금 (USD) | 월 예상 요금 (24h × 30일) |
|---|---|---|---|---|---|---|
| ELK Stack | Elasticsearch, Logstash, Kibana | 8GB RAM, 2 vCPU | 16GB RAM, 4 vCPU | t3.large / m5.xlarge | $0.129 / $0.279 | $92.88 / $200.88 |
| Grafana + Loki | Grafana, Loki | 1GB RAM, 1~2 vCPU | 2~4GB RAM, 2 vCPU | t3.micro / t3.medium | $0.017 / $0.052 | $12.24 / $37.44 |
실제로 저는 이전 사이드 프로젝트에서 t3a.small 인스턴스로도 Loki, Promtail, Grafana 스택을 무리 없이 운영한 경험이 있었습니다.
OpenTelemetry 적용하기: 단계별 진화
모니터링 시스템 구축은 한 번에 완성된 것이 아니라, 점진적으로 개선해나간 과정이었습니다.
1단계: 각 서비스에 직접 OpenTelemetry Endpoint 설정
처음에는 기존 EC2 환경에서 빠르게 적용하기 위해, 각 서비스마다 OpenTelemetry Collector endpoint를 직접 설정하는 방식으로 시작했습니다.
장점:
- 빠른 적용: 기존 인프라 변경 없이 설정만으로 적용 가능
- 간단한 구조: 별도의 복잡한 설정 없이 endpoint만 설정
단점:
- 관리 포인트 증가: 각 서비스마다 개별 설정 필요
- 일관성 유지 어려움: 서비스마다 설정이 달라질 수 있음
- 업데이트 번거로움: OpenTelemetry 설정 변경 시 모든 서비스 개별 수정 필요
실제 적용 예시 (application.yml):
| |
각 서비스의 의존성에 OpenTelemetry Java Agent를 추가했습니다:
| |
이 방식으로 약 2개월간 운영하면서, 모니터링 시스템의 효과를 확인할 수 있었습니다. 하지만 서비스가 늘어나면서 관리의 어려움도 점점 커졌습니다.
otel 버전을 업해야하거나 공통적인 설정을 변경해줘야한다면 모든 서비스에 직접 하나하나 적용을 해줘야 했으니까요.
2단계: 쿠버네티스 도입과 사이드카 패턴으로 전환
6월부터 쿠버네티스 환경으로 점진적으로 이관하면서, OpenTelemetry Collector를 사이드카 패턴으로 구현했습니다.
사이드카 패턴의 장점:
- 애플리케이션 코드 변경 최소화: 기존 서비스 코드를 크게 수정하지 않고도 텔레메트리 데이터 수집 가능
- 일관된 데이터 수집: 모든 서비스에 동일한 방식으로 적용 가능
- 독립적인 업데이트: 애플리케이션과 모니터링 시스템을 독립적으로 업데이트 가능
- 중앙 관리: ConfigMap으로 설정을 중앙에서 관리
실제 구현은 다음과 같이 진행했습니다.
- OpenTelemetry Java Agent 적용: Init Container로 Agent 다운로드
- 사이드카 컨테이너 구성: 각 서비스 Pod에 OpenTelemetry Collector 사이드카 컨테이너 추가
- 파이프라인 설정: 로그, 메트릭, 트레이스 데이터를 각각 Loki, Prometheus, Tempo로 전송하도록 설정
아래는 실제 이벤트 서비스의 배포 설정 일부입니다.
| |
OpenTelemetry Collector 설정은 ConfigMap으로 중앙에서 관리합니다:
| |
두 방식의 비교
| 구분 | 직접 Endpoint 설정 | 사이드카 패턴 |
|---|---|---|
| 적용 환경 | EC2, VM | Kubernetes |
| 설정 위치 | 각 서비스 내부 | ConfigMap (중앙 관리) |
| 관리 복잡도 | 높음 (개별 관리) | 낮음 (중앙 관리) |
| 일관성 | 보장 어려움 | 보장됨 |
| 업데이트 | 각 서비스 재배포 필요 | ConfigMap만 수정 |
| 리소스 사용 | 약간 적음 | 약간 많음 (사이드카 오버헤드) |
| 적용 속도 | 빠름 | 상대적으로 느림 (K8s 필요) |
시스템 도입 효과: 장애 감지 프로세스의 변화
새로운 모니터링 시스템 도입 후, 장애 감지 프로세스가 다음과 같이 변화했습니다.
문제 발생 → 알림 수신 → 문제 인식 → 원인 파악 → 해결이제는 사용자가 CS로 문의하기 전에 개발팀이 먼저 문제를 인지하고 대응할 수 있게 되었습니다. 특히 다음과 같은 효과가 있었습니다:
- 장애 감지 시간 단축: 평균 감지 시간이 수 시간에서 수 분으로 단축
- 선제적 대응 가능: 사용자 영향이 커지기 전에 문제 해결 가능
- 정확한 원인 파악: 로그, 메트릭, 트레이스를 통합적으로 분석하여 정확한 원인 파악 가능
- 반복적인 문제 예방: 패턴 분석을 통한 사전 예방 조치 가능
실제 사례: 모니터링 시스템의 효과
모니터링 시스템 구축 후, 저희는 이전에는 발견하지 못했던 여러 문제들을 발견하고 해결할 수 있었습니다. 그중 대표적인 사례가 ‘월세’ 검색 기능에서 발생한 예외였습니다.
이 문제는 네이밍 컨벤션 불일치로 인한 것이었는데, 서비스 A에서는 월세를 ‘monthly’로, 서비스 B와 연결된 데이터베이스에서는 ‘rent’로 정의하고 있었습니다. 문제는 단순한 네이밍 불일치에 그치지 않았습니다. 데이터베이스 프로시저의 파라미터 중 ‘거래 유형’ 필드는 문자열 길이가 제한되어 있었고(VARCHAR(5)), ‘monthly’(7자)는 이 제한을 초과하여 예외가 발생했던 것입니다. (해당 케이스 관련 글 - 네이밍 컨벤션의 부재는 장애로 이어진다.)

이 문제는 사용 빈도가 낮은 기능이었기 때문에 오랫동안 발견되지 않았습니다. 기존 시스템에서는 사용자가 CS로 문의해야만 알 수 있었던 문제였지만, 새로운 모니터링 시스템 덕분에 실시간으로 감지하여 사용자 신고 없이도 빠르게 해결할 수 있었습니다.
이처럼 모니터링 시스템은 사용자가 불편함을 겪기 전에, 또는 사용자가 불편함을 겪더라도 CS로 문의하지 않아 개발팀이 인지하지 못했던 문제들을 발견하고 해결할 수 있게 해주었습니다.
알림 시스템 구성
Grafana의 알림 기능을 활용하여 다음과 같은 알림 규칙을 설정했습니다.
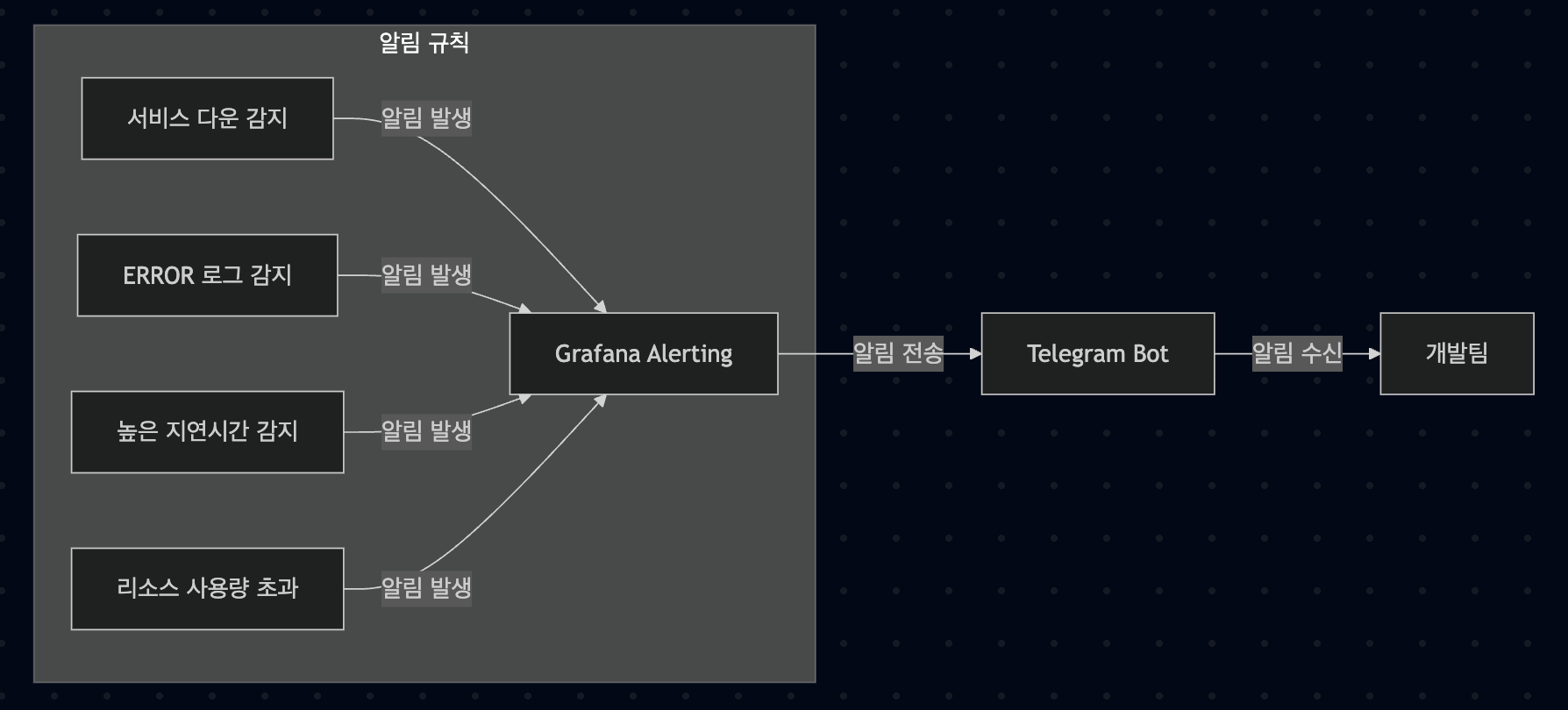
- 서비스 다운 알림: 인스턴스 중 하나라도 다운되면 알림 발송
- 에러 로그 알림: ERROR 레벨 로그 발생 시 알림 발송
- 높은 지연시간 알림: API 응답 시간이 임계값을 초과할 경우 알림 발송
- 리소스 사용량 알림: CPU, 메모리 사용량이 임계값을 초과할 경우 알림 발송
알림은 Telegram을 통해 실시간으로 전송되며, 각 알림에는 문제 해결을 위한 Runbook 링크가 포함되어 있어 빠른 대응이 가능합니다.
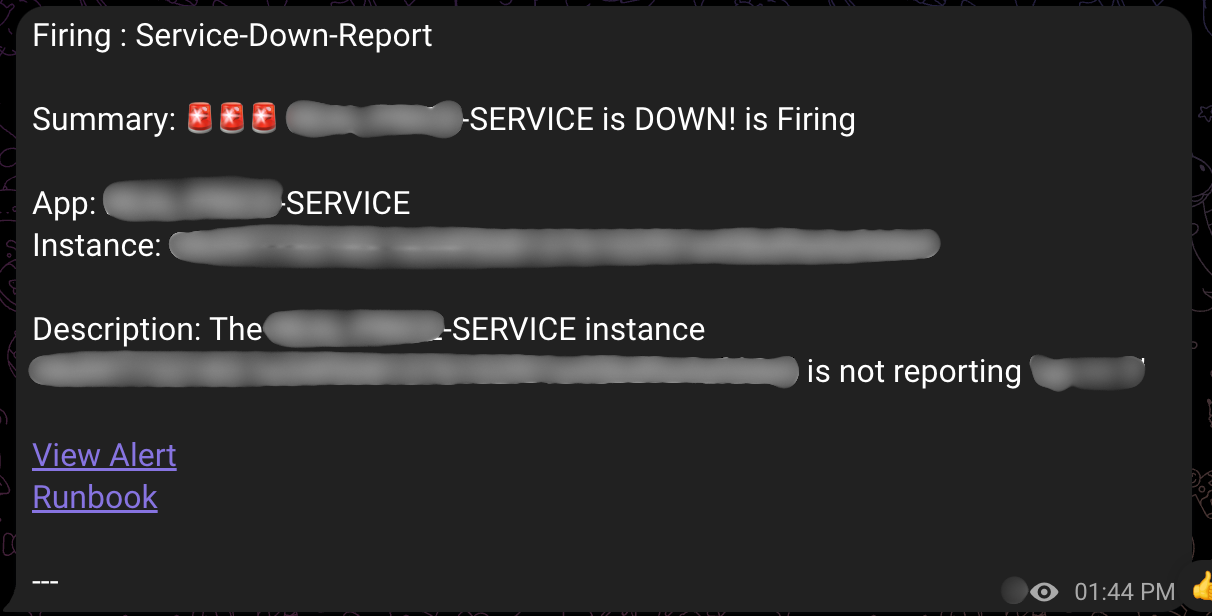
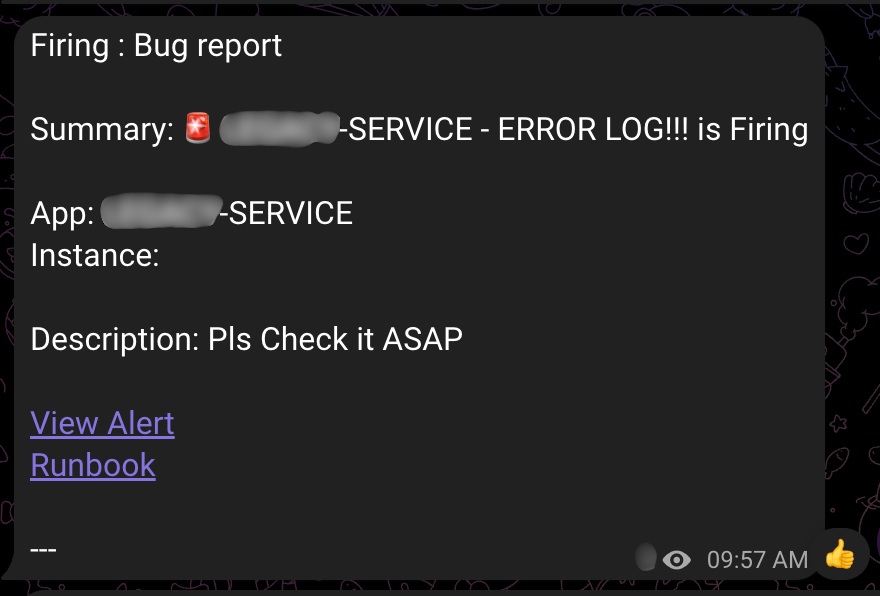
위 이미지는 실제 운영 중인 시스템에서 발생한 알림의 예시입니다. 알림 메시지에는 다음과 같은 정보가 포함됩니다.
- 알림 유형: ‘Firing’(문제 발생) 또는 ‘Resolved’(문제 해결)
- 알림 이름: ‘Service Down Report’(서비스 다운) 또는 ‘Bug Report’(에러 로그)
- 서비스 정보: 어떤 서비스에서 문제가 발생했는지 표시
- Runbook 링크: 문제 해결을 위한 가이드 및 문제 탐색 링크
이러한 상세한 정보 덕분에 개발팀은 문제 상황을 빠르게 파악하고 적절히 대응할 수 있게 되었습니다.
트레이스와 APM을 통한 성능 개선
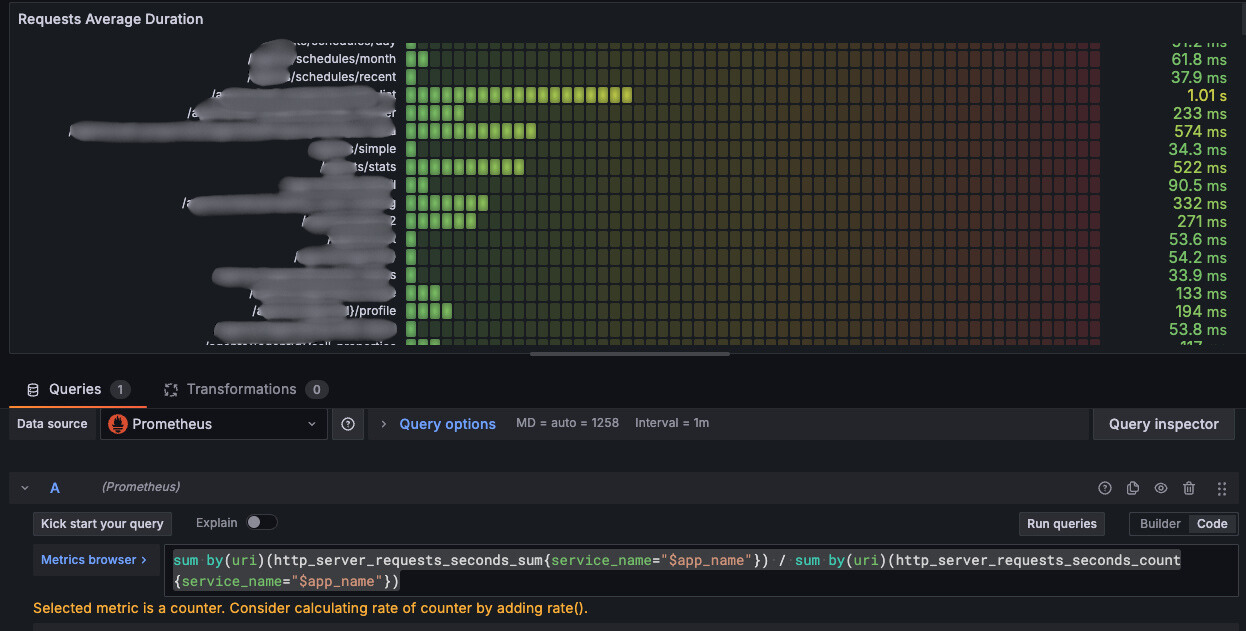
Prometheus의 메트릭을 분석하여 개선이 필요한 API를 먼저 특정하고
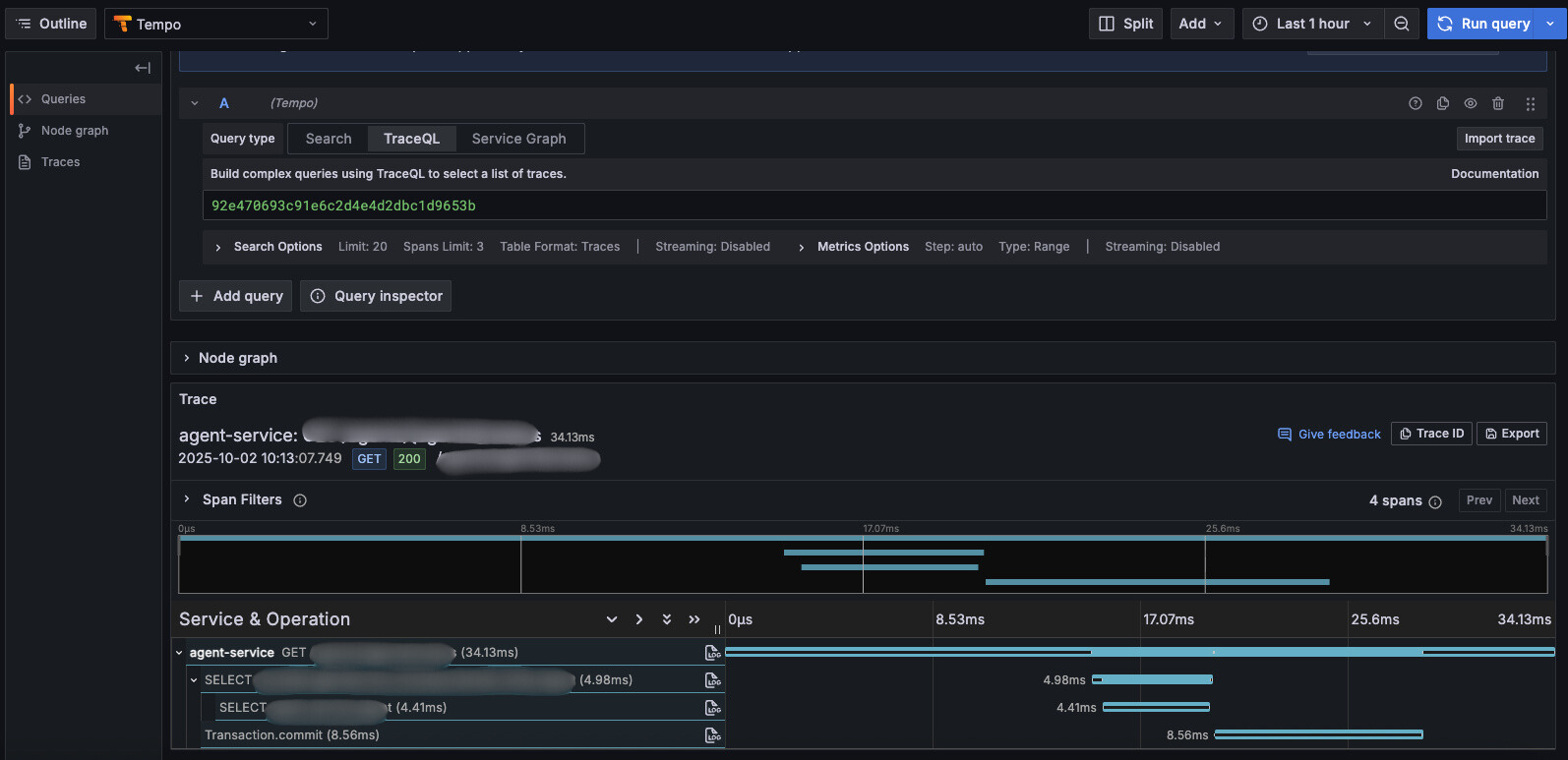
APM인 Tempo를 통해 요청별로 병목지점을 파악할 수 있기 때문에 응답 속도 개선이 필요한 부분을 빠르게 특정 할 수 있게 됐습니다.
회고: 점진적 개선의 중요성
모니터링 시스템 구축을 돌이켜보면, 완벽한 시스템을 한 번에 만들려고 하지 않은 것이 성공의 핵심이었던 것 같습니다.
1단계 (4월): 빠르게 적용 가능한 방식으로 시작
- 각 서비스에 직접 endpoint 설정
- 빠르게 효과 확인
- 문제점 파악
2단계 (6월~): 개선된 아키텍처로 전환
- 쿠버네티스 도입과 함께 사이드카 패턴 적용
- 중앙 관리로 운영 효율성 향상
- 확장성 확보
만약 처음부터 “완벽한” 쿠버네티스 + 사이드카 구조를 만들려고 했다면, 시간이 훨씬 오래 걸렸을 것이고 그 사이에 더 많은 장애를 놓쳤을 것입니다.
“빠르게 시작하고, 점진적으로 개선하라” 는 교훈을 얻을 수 있었습니다.
결론
모니터링 시스템 구축을 통해 저희 팀은 서비스 안정성과 사용자 경험을 크게 향상시킬 수 있었습니다. 특히 사용자가 불편함을 겪고 문의하기 전에 문제를 감지하고 해결하여 서비스의 사용자 이탈이라는 크리티컬한 문제의 가능성을 낮췄다는 점에서 가장 큰 성과라고 생각합니다.
모니터링 시스템은 단순히 기술적인 도구가 아니라, 서비스의 품질과 사용자 경험을 향상시키는 중요한 인프라라고 생각합니다. 특히 마이크로서비스 아키텍처에서는 통합된 관측성이 더욱 중요하다고 생각합니다.
혹시 마찬가지로 모니터링, 예외 알림 시스템이 구축되어있지 않으셨거나 관련된 내용을 찾고 계셨던 분들께 조금이나마 도움이 됐길 바라며 이만 글을 마치겠습니다. 감사합니다!