배포만 하면 느려지는 API, JVM Cold Start 문제 85% 개선하기
들어가며
최근 저희 팀은 Docker Compose 기반의 운영 환경을 쿠버네티스로 전환했습니다. 확장성, 자동화, 무중단 배포 등 MSA 환경에서 필요한 기능들을 제대로 활용하기 위한 선택이었죠.
전환 후 메트릭을 살펴보다가, 묘한 패턴을 발견했습니다.
배포 직후 몇 분간 첫 API 요청이 유독 느리다는 거였죠. 평소엔 100~200ms인 응답이 배포 직후엔 1.2~1.4초씩 걸리는 상황이었습니다. 😱
“배포만 하면 느려지네?”
처음엔 배포 과정의 문제인가 싶었는데, 시간이 지나면 자연스럽게 빨라지는 걸 보고 확신했습니다. JVM Cold Start 문제였습니다.
이 글은 Kubernetes의 startupProbe와 JVM Warm-up을 저희 서비스에 적용한 과정을 기록하고 공유하려 합니다.
문제: 배포 직후 첫 요청이 너무 느리다
증상
저희 회사 서비스는 MSA로 구성되어 있고, 각 서비스가 Spring Boot + Kotlin으로 작성되어 있습니다. 배포는 쿠버네티스 위에서 이루어지고있고 배포 직후 다음과 같은 현상이 반복되었습니다.
- 첫 요청 API: 1.19~1.39s (1,190~1,390ms)
- 두 번째 요청부터: 100~200ms
약 7~14배 차이였습니다. 😭

배포 직후 첫 요청 테스트 응답 시간 - 1,000ms~1,300ms
원인 분석
JVM 기반 애플리케이션의 숙명이라고 할 수 있는 JIT(Just In Time) 컴파일러의 특성 때문이었습니다.
JVM은 처음 코드를 실행할 때 인터프리터 모드로 동작합니다. 자주 사용되는 코드(Hot Spot)를 찾아내면 그제서야 네이티브 코드로 최적화하는 구조죠. 즉, 첫 요청은 희생양이 되는 겁니다.
| 단계 | 실행 방식 | 속도 |
|---|---|---|
| Cold Start (첫 실행) | 인터프리터 모드 | 느림 |
| Warm-up 완료 | JIT 최적화 완료 | 빠름 |
여기에 Kubernetes 환경의 특성이 더해집니다:
- Pod는 언제든 재시작됩니다 (배포, 스케일링, 장애)
- 매번 새로운 JVM이 Cold Start 상태로 시작
- 첫번째 사용자 요청이 Warm-up 희생양이 됨
“이거 그냥 놔둘 수 없다"는 생각이 들었습니다.
기존에는 왜 문제가 안 됐을까?
사실 이 문제는 새로운 게 아니었습니다. Docker Compose로 운영할 때도 Cold Start는 있었죠. 하지만 컨테이너가 한 번 뜨면 오래 살아있었기 때문에, 배포 시에만 잠깐 문제가 됐을 뿐입니다.
쿠버네티스는 다릅니다.
Kubernetes는 Pod를 “Cattle, not Pets” 로 대합니다. 언제든 죽일 수 있고, 죽을 수 있는 존재로 보는 거죠.
- Rolling Update: 배포 시 새 Pod가 계속 생성됨
- Auto Scaling: 부하에 따라 Pod가 늘었다 줄었다 함
- Node 재시작: 인프라 이슈로 Pod가 재배치됨
즉, Pod가 재생성되는 빈도가 훨씬 높아졌고, 그만큼 사용자가 Cold Start 상태의 Pod에 요청을 보낼 확률도 높아진 겁니다.
해결 방법을 찾아서
“이거 우리만 겪는 문제는 아닐 텐데…”
검색을 시작했습니다. 역시나 많은 회사에서 이미 비슷한 문제를 겪고 해결했더라고요.
- OLX는 CPU 리소스를 동적으로 조정하는 방법을 공유했고
- BlaBlaCar는 startupProbe + Warm-up 엔드포인트 패턴을 사용했고
- 국내 기술 블로그에서도 실제 적용 사례를 찾을 수 있었습니다
“이게 표준 패턴이구나. 우리도 적용해보자”
해결 과정: startupProbe + JVM Warm-up
전략
핵심 아이디어는 두 가지입니다:
- Warm-up 실행: “사용자가 요청하기 전에 우리가 먼저 요청해서 JVM을 깨워놓자”
- Warm-up 대기: “Kubernetes가 warm-up 완료를 기다리도록
startupProbe를 설정하자”
startupProbe는 warm-up을 실행하는 게 아니라, warm-up 완료를 확인하고 기다리는 역할을 합니다.
1단계: Kubernetes Probe 이해하기
Kubernetes에는 3가지 Probe가 있습니다:
| Probe | 용도 | 실패 시 동작 |
|---|---|---|
| livenessProbe | 컨테이너가 살아있는지 확인 | Pod 재시작 |
| readinessProbe | 트래픽을 받을 준비가 됐는지 확인 | Service에서 제외 |
| startupProbe | 애플리케이션이 시작됐는지 확인 | 성공할 때까지 다른 Probe 비활성화 |
우리가 필요한 건 startupProbe입니다.
왜 startupProbe가 필요한가?
- warm-up이 오래 걸리면(예: 1~2분) livenessProbe가 먼저 실패해서 Pod를 재시작시킬 수 있음
- startupProbe가 성공할 때까지
readinessProbe와livenessProbe가 비활성화됨 - 따라서 warm-up 시간을 안전하게 확보할 수 있음
2단계: Warm-up 구현
여러 레퍼런스를 참고해 다음과 같이 구현했습니다.
(1) WarmupHealthIndicator 생성
Spring Actuator와 통합되는 Health Indicator를 만듭니다:
| |
(2) Warmup 로직 구현
애플리케이션 시작 시 자동으로 실행되도록 ContextRefreshedEvent를 사용합니다:
| |
(3) application.yml 설정
| |
핵심 포인트:
ContextRefreshedEvent: HTTP 포트 오픈 전에 실행되어 warm-up 중 요청 유입 방지AtomicBoolean: 동시성 제어로 중복 실행 방지HealthIndicator: Kubernetes probe와 자연스럽게 통합- readiness에만 포함: warm-up 완료 전까지 트래픽 차단
3단계: Kubernetes Probe 설정
중요: startupProbe는 필수입니다!
warm-up이 오래 걸릴 경우 livenessProbe가 Pod를 재시작시킬 수 있기 때문에, startupProbe로 warm-up 완료를 기다려야 합니다.
| |
설정 의도:
- startupProbe: warm-up 완료를 기다리며, 완료될 때까지 다른 probe 비활성화
/actuator/health/readiness: warmup HealthIndicator 포함하여 warm-up 완료 전까지 DOWN 반환failureThreshold: 24: 최대 2분 동안 warm-up 시간 보장- liveness에서 warmup 제외: warm-up이 길어져도 Pod 재시작 방지
- CPU
limits: 1800m: Warm-up 중 충분한 CPU 제공
전체 동작 흐름
위 설정들이 어떻게 협력하는지 전체 흐름을 살펴보겠습니다:
1. Pod 시작
↓
2. Spring Boot 애플리케이션 시작
↓
3. ContextRefreshedEvent 발생
→ WarmupRunner가 warm-up 실행 시작
→ WarmupHealthIndicator는 DOWN 상태 유지
↓
4. Warm-up 진행 중...
→ 주요 API들을 10번씩 반복 호출
→ JIT 컴파일러가 코드 최적화
→ startupProbe가 5초마다 /actuator/health/readiness 체크
→ DOWN이므로 계속 대기 (최대 24번)
↓
5. Warm-up 완료
→ WarmupHealthIndicator.complete() 호출
→ WarmupHealthIndicator가 UP으로 변경
↓
6. startupProbe 성공
→ /actuator/health/readiness가 UP 반환
→ startupProbe 성공
↓
7. readinessProbe, livenessProbe 활성화
→ readinessProbe가 Service에 Pod 등록
↓
8. 트래픽 수신 시작
→ 이미 warm-up 완료된 상태로 요청 처리핵심 포인트:
- Warm-up 실행:
ContextRefreshedEvent리스너가 담당 - Warm-up 대기:
startupProbe가 담당 - startupProbe는 warm-up을 실행하지 않고, warm-up 완료를 기다릴 뿐입니다
4단계: CPU 리소스 최적화
여기서 중요한 발견이 있었습니다. 처음엔 CPU limit을 1000m으로 설정했는데, Warm-up이 제대로 안 되더라고요.
알고 보니 JVM Warm-up 중에는 평소보다 3배 정도의 CPU가 필요했습니다. JIT 컴파일러가 코드를 최적화하면서 CPU를 많이 사용하거든요.
| |
Kubernetes의 CGroup CPU Throttling 때문에 limit에 걸리면 Warm-up이 느려집니다. 그래서 Warm-up 중엔 충분한 CPU를 보장하고, 평상시엔 requests로 최소 리소스만 예약하도록 했습니다.
결과: 85% 개선
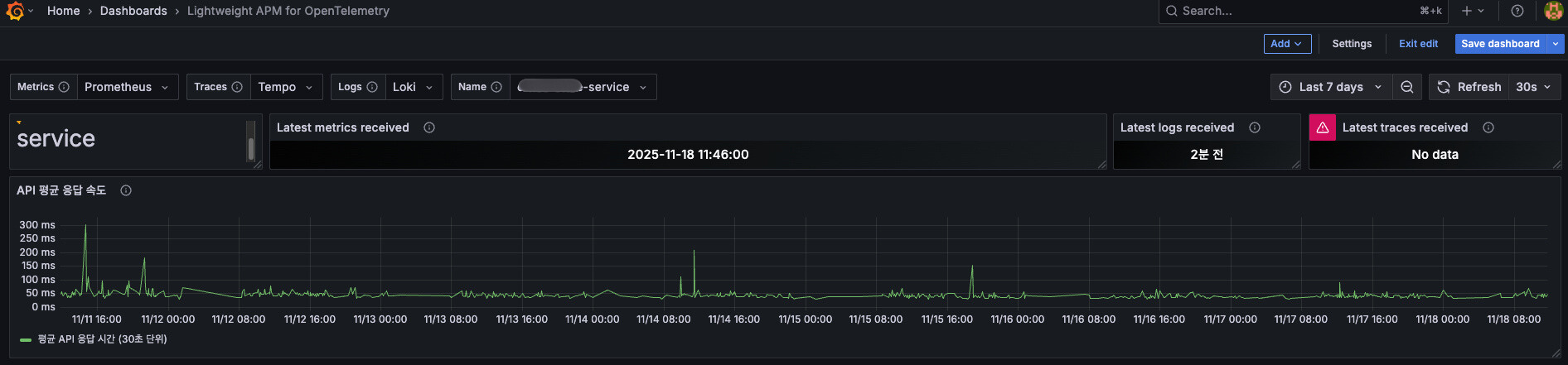
Warm-up 적용 후 첫 요청 응답 시간 - 평균 150~230ms
Before (Cold Start)
- 첫 요청 API: 1,190~1,390ms
- 두 번째 요청: 100~200ms
- 사용자 체감 불편함: 높음
After (Warm-up 적용)
- 첫 요청 API: 150~230ms
- 두 번째 요청: 100~200ms
- 사용자 체감 불편함: 없음
약 85% 개선되었고, 무엇보다 첫 요청과 이후 요청의 차이가 대폭 줄어들었습니다.
긍정적 효과
- Auto Scaling 안정화: 새 Pod가 바로 트래픽을 처리할 수 있어서 스케일링이 부드러워짐
- 사용자 이탈 감소: 배포 시간대에 첫 페이지 로딩이 느려서 이탈하던 사용자들이 줄어듬
적용 시 주의사항
다른 회사들의 적용 사례를 보면 다음과 같은 점들을 주의해야 합니다.
1. 배포 시간 증가
문제: Warm-up 때문에 Pod가 Ready 상태가 되는 시간이 늘어날 수 있습니다.
해결: Rolling Update 전략을 조정하면 됩니다.
| |
이렇게 하면 배포는 조금 느려지지만, 무중단 배포가 보장됩니다.
2. 외부 API Warm-up
문제: 외부 API를 Warm-up에 포함시키면 외부 시스템에 불필요한 부하를 전파하게 됩니다.
해결: Warm-up은 내부 API 또는 더미 데이터 처리 로직으로만 제한하는 게 좋습니다.
| |
3. DB 커넥션 이슈
문제: Warm-up 중 DB 조회 API를 호출하면 커넥션 풀이 고갈될 수 있습니다.
해결:
- DB 조회가 필요한 API는 모킹하거나
- 커넥션 풀 크기를 조정하면 됩니다
| |
배운 점
1. JVM 특성을 이해하는 게 중요하다
Java/Kotlin을 쓴다고 해서 JVM을 모르고 넘어가면, 이런 성능 문제를 해결할 수 없습니다. JIT 컴파일러, GC, 클래스 로딩 등 JVM 내부 동작 원리를 이해하는 게 중요하다는 걸 다시 느꼈습니다.
2. Kubernetes Probe는 단순한 Health Check가 아니다
Kubernetes의 3가지 Probe를 상황에 맞게 전략적으로 활용하는 게 중요합니다.
| 상황 | 적합한 Probe |
|---|---|
| 느린 시작 (JVM Warm-up) | startupProbe |
| 트래픽 수신 준비 확인 | readinessProbe |
| 프로세스 살아있는지 확인 | livenessProbe |
3. 리소스는 여유있게, 하지만 낭비하지 말고
CPU requests와 limits의 차이를 이해하고 활용하는 게 중요합니다.
requests: 평상시 필요한 최소 리소스 (스케줄링 기준)limits: 최대 사용 가능한 리소스 (Throttling 기준)
Warm-up처럼 일시적으로 많은 리소스가 필요한 경우, limits를 넉넉하게 설정하되 requests는 평상시 사용량에 맞추는 게 효율적입니다.
4. 모니터링이 모든 것의 시작이다
이 문제를 발견한 것도, 개선을 확인한 것도 모두 메트릭 덕분이었습니다. Prometheus + Grafana로 API 응답 시간을 모니터링하지 않았다면, 아마 이 문제를 모르고 넘어갔을 겁니다.
참고: Spring Boot + Kubernetes 기반에서 웜업 적용하기 - LINE Engineering Improving JVM Warm-up on Kubernetes - OLX Engineering Kubernetes 공식 문서 - Liveness, Readiness, Startup Probes
마치며
JVM Cold Start 문제는 쿠버네티스 환경에서 피할 수 없는 숙제입니다. 하지만 startupProbe와 JVM Warm-up을 적절히 활용하면, 사용자 경험을 해치지 않으면서도 컨테이너 오케스트레이션의 장점을 누릴 수 있습니다.
이 글이 비슷한 문제를 겪고 있는 분들께 도움이 되길 바랍니다. 😊