3AM Error Alerts? Let AI Fix Them: Automating Error Response with OpenClaw
Hi, I’m Jeongil Jeong, a 3-year backend developer working at a proptech platform.
TL;DR
I automated 3AM error alert responses with OpenClaw.
Using Loki/Tempo polling + Telegram Forward hybrid approach, AI handles everything from error analysis to PR creation, while humans only review code.
AI agents are increasingly becoming central to how developers collaborate these days.
Looking at developer communities, all the hot keywords are related to AI and AI agents. According to GitHub’s 2024 Developer Survey, over 97% of 2,000 developers from the US, Brazil, India, and Germany reported using AI coding tools, and 59-88% of organizations are allowing or actively encouraging AI tool usage.
While many companies were hesitant to adopt AI tools due to security, privacy, and accuracy concerns, more companies are now adopting AI agents like GitHub Copilot and Claude Code. AI has evolved beyond simple “code completion” to autonomously reading files, executing commands, modifying code, and creating PRs.
In this context, I started thinking about how to delegate repetitive tasks to AI and focus on what really matters.
This post is about how I automated error alert responses using AI agents.
The Daily Life of Service Operations: Wrestling with Error Alerts
If you’re operating a service, you’ve probably experienced your phone ringing at unpredictable times—3 AM, 7 PM, 10 AM—everyone’s been there at least once.
🚨 legacy-service - ERROR LOG!!! is Firing
Description: Pls Check it ASAPWhen this alert comes, I rub my eyes, open my laptop, check the Grafana dashboard, dig through error logs in Loki, find the trace_id to track request flow in Tempo, and analyze the codebase to find the root cause.
flowchart LR
A["🚨 Error Alert"] --> B["Check Loki Logs"]
B --> C["Trace in Tempo"]
C --> D["Analyze Code"]
D --> E["Identify Root Cause"]
E --> F["Create Issue/Ticket"]
F --> G["Fix Code"]
G --> H["Create PR"]
30 minutes to 1 hour. Even for simple bugs, it takes this long. Complex cases take much longer.
This process is probably common for any developer operating a service. The tools and templates might differ slightly between companies and services, but the overall framework is similar.
So here’s the question: Can AI do this instead?
Handling errors with the same pattern repeatedly, I had this thought. Checking logs, tracing, analyzing code… these steps are standardized. Can’t AI do this? This question started everything.
Defining the Challenges
First, I broke down what I normally do. To know how to automate, I need to know what I’m doing first.
First, I check error logs when they come in.
“Checking” here includes two things: detecting the error alert when it arrives, and querying Loki/Tempo to retrieve and understand the related logs and traces.
Next, I need to explore the codebase based on error logs to analyze the cause and identify the error point. The challenge is that our company’s service is built on a microservice architecture, so I often need to look at not just the service where the error occurred, but also related services.
And finally, create issues/tickets → fix code → create PR.
So, for AI to complete all these tasks instead of me, here are the challenges:
- Error detection
- Log/trace querying
- Root cause analysis and error point identification
- Issue/ticket creation
- Code fixing
- PR creation
First Attempt: Semi-Automation with MCP
So initially, I created a tool called error-autopilot using MCP (Model Context Protocol).
flowchart LR
subgraph MCP["MCP-based Semi-Automation"]
Human["👨💻 Developer"] -->|"Manual Trigger<br/>(/autopilot)"| Claude["Claude Code"]
Claude <-->|"JSON-RPC"| Server["error-autopilot<br/>MCP Server"]
Server --> Loki["Loki"]
Server --> Tempo["Tempo"]
Claude -->|"Analysis Result"| Issue["GitHub Issue"]
end
It was a tool where the MCP server called Loki/Tempo APIs to query logs. When a developer typed the /autopilot command to the agent, the MCP server would query and analyze error logs and traces from Loki/Tempo.
This made log querying and trace analysis possible. But how about the third challenge, root cause analysis and error point identification?
I used a somewhat brute-force method. Since it was an MCP just for me, I let Claude Code read the codebase I already had locally.
I used the MCP Skills feature to map codebase paths of services to explore after checking error logs. This way, even with a microservice architecture, I could read code from all related services.
I identified related services through Tempo (APM) and read and analyzed code through pre-mapped codebase paths.
| |
After analyzing the codebase and identifying the cause, it would create a GitHub issue.
It was quite useful. The time spent digging through logs was significantly reduced.
MCP Action Screen
| Trigger | Action | Result | Created ISSUE |
|---|---|---|---|
But the Limitations Were Clear
As I used it, I started noticing shortcomings. The problem was manual triggering.
When an alert came, I had to manually type the /autopilot command or say something like “check error logs.” Log querying and analysis were automated, but I still had to start it manually.
The first of the six challenges, “error detection,” wasn’t automated.
It wasn’t really automation. It was “semi”-automation. For automation, AI needed to detect errors on its own and start the process.
Discovering OpenClaw: Notifications as Triggers
Then I discovered OpenClaw, a very hot topic in developer communities recently.
OpenClaw is an open-source LLM-based personal assistant that runs locally with access to shell, file system permissions, and computer control capabilities.
Think of it as “an AI assistant installed on your computer.” But what’s different from existing AI agents? Claude Code also runs locally, right? It also has shell and file system access.
OpenClaw’s real differentiator is that it’s in 24/7 standby mode, detecting messages in real-time from Telegram, Slack, Discord, etc. (assuming your local machine stays on).
Telegram ──┐
WhatsApp ──┤
Slack ──┼──▶ [ Gateway ] ──▶ AI Model (Claude/OpenAI)
Discord ──┤ │
Web UI ───┘ ▼
Files, Browser,
Command Execution, etc.- Gateway: Central process managing all channel connections
- Workspace: The AI agent’s “home” (
~/.openclaw/workspace/) - Skills: Workflows defined in markdown
Traditional agents required me to type commands for AI to respond. But OpenClaw automatically responds when a message arrives.
You might have already noticed—this means error alert → AI agent auto-analysis → PR creation automation becomes possible.
flowchart TB
subgraph After["OpenClaw (Automation)"]
Alert2["Grafana Alert"] --> TG2["Telegram"]
TG2 -->|"Auto Trigger"| AI2["AI Agent"]
AI2 --> PR["PR Creation"]
end
subgraph Before["MCP (Semi-Automation)"]
Alert1["Grafana Alert"] --> TG1["Telegram"]
TG1 --> Human1["👨💻 Developer"]
Human1 -->|"Manual Trigger"| AI1["AI"]
end
With this setup, when a Grafana Alert sends an alert to a specific messenger, the message itself becomes the trigger, and the agent can automatically start analysis, fix code, and create a PR without human intervention.
Implementation Attempt: Grafana Alert as Trigger
I jumped right into implementation. Here are the key points of how I built error-autopilot with OpenClaw.
First, I defined a persona in ~/.openclaw/workspace/.
OpenClaw asks you to define your name or persona when you first start it.

After defining the identity, it automatically generates these files. I named mine “Son of Victor,” inspired by “Son of Anton” from the TV show Silicon Valley. :)
~/.openclaw/workspace/
├── SOUL.md # Personality and tone
├── USER.md # User information
├── IDENTITY.md # Name and identity
├── BOOTSTRAP.md # Read and deleted on first run
├── MEMORY.md # Long-term memory
├── memory/ # Daily notes
└── skills/ # Workflow definitions
After this basic setup, I moved on to setting up message channels and defining the error auto-analysis Skill.
Since our company’s Grafana Alerts were already configured to send to Telegram, I created a Telegram bot for OpenClaw and connected it.
1. Telegram Channel Setup
I also connected the Grafana Alert dedicated group in Telegram to OpenClaw.
| |
Setting requireMention: false means OpenClaw responds immediately when a message arrives in the group, without needing a mention.
The plan was simpler than expected:
- Grafana sends error alert to Telegram group
- OpenClaw detects message
- Automatically executes error-autopilot Skill
- Identifies error cause and creates issue/PR
2. Skill Definition
In OpenClaw, workflows are defined as markdown documents (Skills).
You don’t need to create a TypeScript server like MCP. Just one markdown file.
| |
AI reads this guide and executes it step by step.
Testing: Does It Work as Expected?
After completing the setup, I tested it. I triggered a simple validation failure exception and sent a message directly to the Telegram group.
🚨 chat-service - ERROR LOG!!!
Description: Pls Check it ASAPOpenClaw responded immediately. It queried Loki, analyzed code, created a GitHub issue, identified the cause, and generated a PR.



It worked perfectly in the test environment. Now it was time to see how it would behave when a real error occurred.
Real World: Telegram Bot API Limitations
A few days later, an actual error occurred.
A Grafana exception alert came to Telegram:
🚨 legacy-service - ERROR LOG!!! is Firing
Description: Pls Check it ASAPBut Son of Victor (OpenClaw) didn’t respond.
It definitely worked in testing, so why not in the real environment? I checked the settings again. No problems. I opened OpenClaw logs. It hadn’t received any messages.
I started checking the differences between test and real environments one by one. Message format was the same, Telegram group ID was the same… the only difference was the sender.
Problem Found: Telegram Bot Inter-Communication Restriction
I found the reason in the documentation.
Telegram Bot API cannot receive messages sent by other bots.
Grafana Bot --[Send Message]--> Telegram Group
↓
OpenClaw Bot (Cannot Receive ❌)
Human --[Send Message]--> Telegram Group
↓
OpenClaw Bot (Can Receive ✅)My test message was sent by a “human,” so it worked. The real alert from Grafana bot was sent by a “bot,” so it didn’t work.
Checking the Telegram Bot API official documentation, this was an intentional security policy. It was designed to prevent infinite loops and spam between bots. A natural choice for security, but it threatened my plan.
Finding Solutions: Real-time vs Polling
With Telegram triggers blocked, I needed to find another way. I checked Slack and Discord, but they had similar restrictions. Slack’s framework filters bot messages, and Discord restricts bot-to-bot communication. Switching messengers wasn’t a fundamental solution.
There were two main approaches:
1. Webhook Approach (Real-time) Grafana sends webhooks directly when errors occur. Add OpenClaw webhook endpoint to Grafana Contact points. This requires either exposing the local environment via Tailscale Funnel or cloud deployment with AWS Lambda, Cloud Run, etc.
2. Polling Approach (Delayed) Periodically query Loki/Tempo directly. Like a CronJob.
But I wondered if real-time triggering was really necessary. Even if an error occurs at 3 AM, I’ll check it in the morning anyway. Do I really need to insist on real-time?
I compared the two approaches:
| Approach | Response Time | Cost | Security | Implementation Difficulty |
|---|---|---|---|---|
| Polling | Delayed by Cron interval | Free | Safe | Low |
| Webhook + Tailscale Funnel | Real-time | Free | External exposure risk | Medium |
| Webhook + Cloud Deployment | Real-time | $5-20/month | Management required | High |
Polling Approach
- Check Loki/Tempo directly at Cron intervals
- Start processing when new error found
- No external exposure, safe local execution
Webhook + Tailscale Funnel
- Expose local environment to internet to receive Grafana webhooks
- Real-time triggering possible but security risks
- Using Tailscale Funnel to expose local is convenient, but once OpenClaw is accessible on the public internet, there are risks like prompt injection or brute-force API calls through malicious webhook requests.
Webhook + Cloud Deployment
- Deploy server to cloud to receive Grafana webhooks
- Real-time triggering possible but costs incurred
- Infrastructure management and security setup required
Choosing Polling Approach
The Tailscale Funnel approach had significant security risks. I could be exposed to various threats like prompt injection, token brute-force, DDoS attacks, so I ruled it out.
The remaining options were cloud deployment or polling. Since real-time wasn’t essential, considering cost and management, I chose the polling approach.
Final Implementation: Periodic Checks with Heartbeat
Having decided on polling, I needed to figure out how to implement it.
Looking at OpenClaw documentation, it provided two methods for periodic task execution.
Implementation Approach Comparison
1. Heartbeat (Built-in OpenClaw)
The main process wakes itself up.
| |
The advantage is simple configuration and management within the OpenClaw process.
The disadvantage is that when the OpenClaw process terminates, it stops too, and requires manual restart after local PC reboot.
2. Cron Job (External Scheduler)
Cron Job is like an external independent alarm waking you up.
| |
The advantage is that even if the OpenClaw main session dies, Cron Job stays alive and continues running, operating independently in an isolated session, making it more stable.
The disadvantage is slightly more complex configuration and separate Cron Job management needed. However, OpenClaw provides UI for managing Cron Jobs, so it wasn’t too difficult.
Selection Rationale
Initially, Cron Job seemed attractive for its stability. It runs independently of the OpenClaw process, after all.
But Heartbeat’s much simpler configuration was a bigger factor. And the supposed disadvantage—“if OpenClaw dies, Heartbeat dies too”—wasn’t actually a problem. OpenClaw registers itself as an OS-level service (macOS LaunchAgent, Linux systemd, etc.) during gateway setup, so even if the process terminates or the PC reboots, it automatically restarts.
So I chose Heartbeat. Simple to configure, and with OpenClaw handling process recovery on its own, it’s just as stable as Cron Job. I set the Heartbeat interval to 30 minutes to check errors every 30 minutes.
Running Heartbeat too frequently could incur high token costs, so I judged 30-minute intervals to be appropriate.
But the 30-minute delay still bothered me. It felt insufficient for complete automation. After some thought, I realized a hybrid approach could work.
flowchart TB
subgraph "Normal Situation (Auto)"
Cron1["⏰ Every 30 min<br/>Heartbeat"] --> Auto["Auto Process"]
end
subgraph "Urgent Situation (Manual)"
Alert["📱 Error Alert<br/>Check"] --> Forward["Message<br/>Forward"] --> Manual["Immediate Process"]
end

Normal Situation: Heartbeat auto-polls every 30 minutes for processing Urgent Situation: Immediate processing by forwarding message in Telegram group
Telegram Forward Mechanism
Telegram has a security policy that blocks bot-to-bot messages. OpenClaw bot can’t directly receive messages sent by Grafana bot.
But what if a human forwards a message sent by a bot?
From Telegram’s perspective, it becomes a message sent by a human. So OpenClaw can receive it.
Grafana Bot → [🚨 Error!] → Telegram Group
↓
Human Forwards
↓
OpenClaw Bot ✅ Can ReceiveChecking the Telegram Bot API official documentation, forwarded messages have a forward_from field, but the message sender becomes the person who executed the forward. In other words, it’s not bypassing the bot-to-bot blocking policy, but rather considered a legitimate use case because explicit human action is involved.
This way, normal situations use 30-minute polling for cost-efficient and secure auto-processing, while urgent situations allow humans to request immediate processing via forward.
Real-World Operation Scenarios
Scenario 1: Auto-Processing (Normal Case) When an error occurs in DEV environment at 3 AM:
- 3:00 - Grafana sends Telegram alert (immediate human notification)
- 3:30 - Heartbeat detects new error in Loki
- 3:35 - OpenClaw completes analysis, creates PR
- 3:36 - Sends processing result to DEV Telegram group (-100XXXXXXXXXX)
- 9:00 - Morning arrival, check and merge PR
Scenario 2: Manual Trigger (Urgent Case) When urgent error occurs in production:
- 10:15 - Check Grafana alert
- 10:16 - Forward message in Telegram
- 10:17 - OpenClaw immediately starts processing
- 10:22 - Analysis complete, PR created
- 10:23 - Sends result to PROD Telegram group (-100YYYYYYYYYY)
Works identically for both DEV/PROD environments, and 30-minute delay is sufficient for most cases. Urgent errors can be handled immediately via forward, and AI analysis runs in the background.
Whether I’m sleeping, in a meeting, or before arriving at work, AI handles analysis and creates PRs.
Automation Achieved
This is how I achieved automation.
flowchart LR
Alert["🚨 3 AM<br/>Error Alert"] --> AI["🤖 AI Agent<br/>(OpenClaw)"]
AI --> PR["📝 PR Created"]
PR --> Morning["☀️ Morning Arrival"]
Morning --> Review["👨💻 Review PR"]
Review --> Merge["✅ Merge or Reject"]
Even if alerts come at 3 AM, by morning arrival:
- Error analysis is complete
- Issue is created
- Code is fixed
- PR is open
I just need to review the issue and PR, then decide whether to merge or reject.
All six challenges defined earlier are now automated:
| Challenge | MCP (Semi-Automation) | OpenClaw (Automation) |
|---|---|---|
| 1. Error Detection | ❌ Manual Trigger | ✅ Heartbeat Auto Polling |
| 2. Log/Trace Query | ✅ | ✅ |
| 3. Root Cause Analysis | ✅ | ✅ |
| 4. Issue Creation | ✅ | ✅ |
| 5. Code Fixing | ❌ | ✅ |
| 6. PR Creation | ❌ | ✅ |
Extension: Performance Bottlenecks Too
Once error automation was running reliably, I applied the same pattern to performance bottleneck detection. It automatically discovers slow APIs from monitoring metrics, analyzes bottleneck points through trace analysis, and suggests improvement directions. I’ll cover this in detail in a separate post if I get the chance.
Don’t Blindly Trust: PR Code Review is Essential
This automation is definitely convenient. But I believe we should never trust it completely.
Just like humans, AI can obviously make mistakes. It can make wrong analyses and suggest inappropriate fixes.
That’s why human intervention is absolutely necessary. So I configured it to always go through code review processes.
I built a multi-agent review system to ensure AI-generated code always goes through verification. (See my previous post)
flowchart LR
AI["🤖 AI Agent<br/>(Code Writing)"] --> PR["Pull Request"]
PR --> Gemini["🤖 Gemini<br/>(Code Review)"]
PR --> CI["🔧 CI/CD<br/>(Automated Verification)"]
Gemini --> Comment["Review Comments"]
CI --> Deco["PR Decoration"]
Comment --> Human["👨💻 Developer"]
Deco --> Human
Human -->|"Review & Merge"| Merge["✅ Merge"]
When PR is created, automatically:
- Gemini Assistant writes code review comments
- CI/CD tools verify (Jacoco, Detekt, ArchUnit, reviewDog)
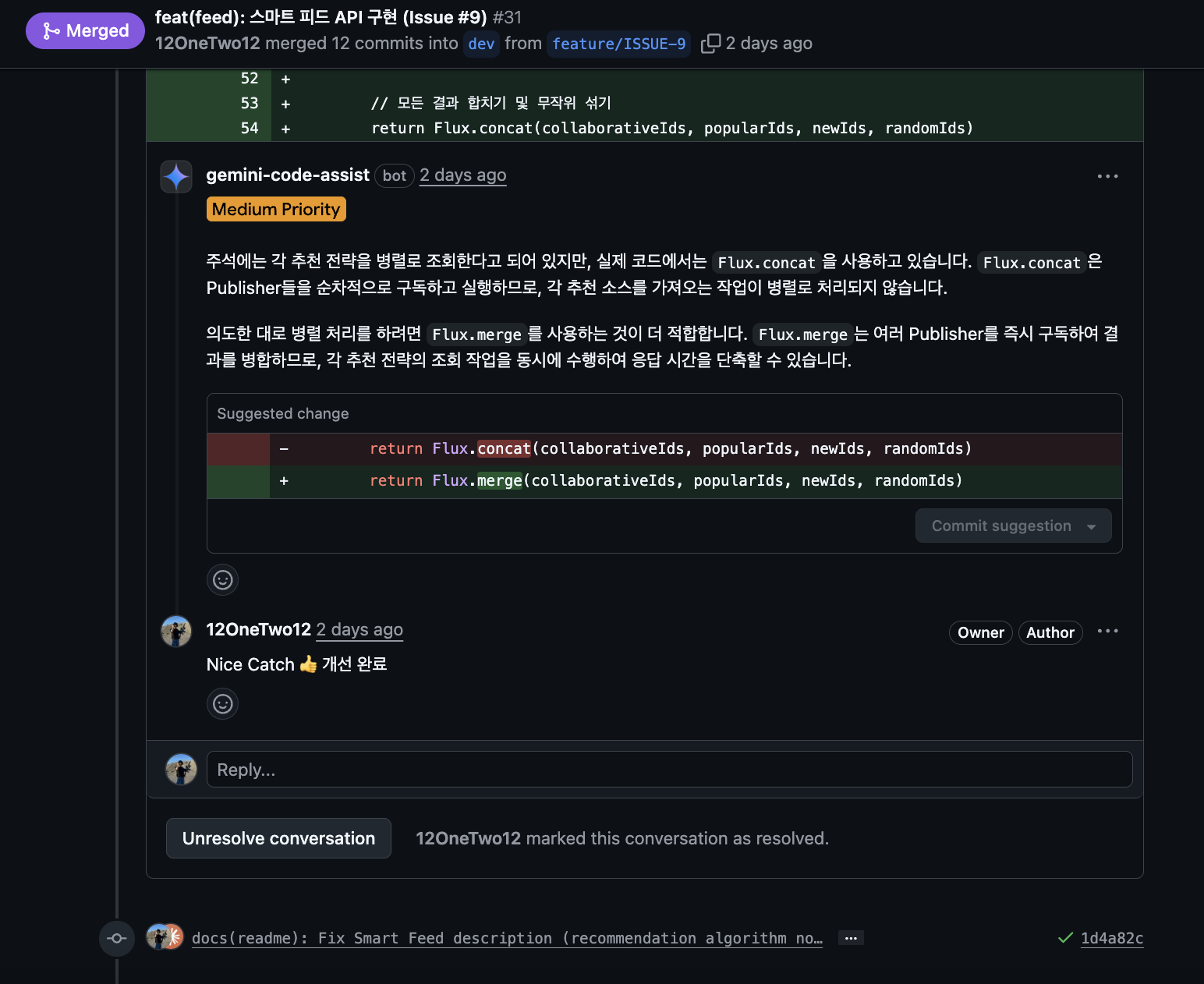
Claude catches what Gemini misses, and automated tools catch what Gemini misses. Multi-agent cross-verification is effective, just like the AgentCoder research (2024) showed.
Before & After
Comparing before and after automation: previously, I directly checked logs, verified traces, analyzed code, created issues, fixed code, and created PRs—everything manually.
If I missed alerts overnight, I had to check them after arriving at work. But now, when I arrive in the morning, I just review the issues and PRs that Son of Victor (OpenClaw) analyzed overnight and check if it did well.
Of course, there are limitations:
Works Well:
- Simple bugs like NPE, type errors
- Repetitive errors with clear patterns
- Cases where cause is obvious from logs
Difficult Cases:
- Complex business logic bugs
- Concurrency/race condition issues
- Security-related issues (risky auto-fix)
So I place more value on “auto-analysis + issue creation” rather than “auto-fix”. When AI does initial analysis, humans can focus on reviewing and making decisions.
Precautions: What You Must Know
OpenClaw is convenient, but there are definitely things to be careful about.
1. Security Issues
OpenClaw agents can access codebases, GitHub tokens, API keys, etc. As convenient as it is, it’s also risky.
Real-World Security Incidents
In January 2026, security researchers discovered numerous OpenClaw instances exposed on Shodan. They were exposed to the public internet without authentication, risking API key and OAuth token leaks.
More seriously, on January 30, 2026, CVE-2026-25253 (CVSS 8.8), a critical one-click RCE vulnerability was discovered. Just by clicking a malicious link or visiting a specific site, attackers could access the local gateway, manipulate settings, and execute privileged actions.
Also, 341 malicious skills were found in ClawHub (OpenClaw’s skill marketplace), with 335 of them attempting to install Atomic Stealer (AMOS), a macOS information-stealing malware.
Rapidly Growing Project’s Limitations
OpenClaw started as Peter Steinberger’s side project and has now transitioned to an organization with multiple maintainers. It has 7 core team members, Jamieson O’Reilly joined as security lead, and it’s supported by 10+ sponsors.
However, resources are still limited compared to its explosive growth rate (100k stars in a week, 2M visitors). The OpenClaw GitHub security page states:
“OpenClaw is a labor of love. There is no bug bounty program and no budget for paid reports.”
It’s an open-source project made with love, so there’s no bug bounty program or budget. One security researcher contacted them multiple times, but got a response saying “too much to do,” causing delayed responses.
This isn’t wrong—most open-source projects operate this way. But users should know that security issue responses might not be as fast as enterprise products.
These incidents made the security risks of using OpenClaw clear:
- Sensitive info exposure:
.envfiles or secrets might enter AI context - GitHub token permissions: If it has PR creation and branch creation permissions, abuse is possible
- Prompt injection: If error logs contain malicious content, AI might perform unintended actions
- MCP Remote vulnerabilities: Command injection RCE vulnerabilities like CVE-2025-6514
So Here’s How I Responded
1) Least Privilege Principle
I first created a separate GitHub service account with minimal permissions only.
| |
2) File System Isolation
I applied the sandbox settings recommended by OpenClaw official documentation.
| |
This way, the agent only operates within ~/.openclaw/sandboxes and cannot access the entire host file system.
3) Environment Variable and API Key Isolation
I didn’t store API keys in plain text in ~/.openclaw/.env, but instead used the system keychain.
| |
4) Brokered Authentication Pattern
Using services like Composio, agents can perform tasks without seeing actual API keys.
AI Agent → Composio Proxy → GitHub API
(API key injection)The agent requests Composio to “create a PR,” and Composio authenticates on the backend and returns only the result.
5) Docker Container Isolation (Optional)
If stronger security is needed, you can isolate with Docker containers.
| |
But since I’m using it in a local environment, I didn’t apply Docker. I judged that file system isolation and minimal privilege account were sufficient.
6) Network Isolation
I absolutely didn’t expose it to the external internet. Methods like Tailscale Funnel have risks like prompt injection and DDoS, so I excluded them.
Instead, I chose the polling approach mentioned above to not receive external requests.
I believe safety measures are better in multiple layers. Especially since OpenClaw is still in early stages, unexpected vulnerabilities could be discovered, so it’s better to approach conservatively.
2. Cost
LLM API calls occur every time alerts come. Claude API costs aren’t trivial.
- If alerts come frequently, costs can spike rapidly
- Especially when doing code analysis, token consumption is high
That’s why you need to set intervals appropriately to avoid hitting token limits and manage costs.
3. Risk of Incorrect Fixes
If AI analyzes incorrectly, it can create even bigger bugs.
- Might break business logic while trying to fix simple NPE
- More dangerous if codebase has no tests
So never auto-merge, always require human review before merge. This is why I attached Gemini code review + automated tools mentioned earlier.
4. Not Yet Properly Validated
Lastly, what I consider most important: as the AI ecosystem rapidly develops, new tools emerge daily, trends change, and unexpected problems can arise.
Yesterday oh-my-opencode was trending, today OpenClaw is hot, tomorrow who knows what will come next. In this rapidly evolving environment where tools emerge and develop so quickly, nobody knows what bugs early-stage tools might have.
When I looked into it, OpenClaw is a side project that Austrian developer Peter Steinberger started on a weekend in November 2025. He developed it rapidly with an AI-centric development workflow. In a Pragmatic Engineer interview, he mentioned “I ship code I don’t read,” meaning he delegates much of the work to AI.
It achieved 100k GitHub stars in a week and recorded 2 million visitors in a single week with explosive growth, yet it’s a project that started just 3 months ago. While it has now transitioned to an organization with 7 core team members, it’s still a very rapidly changing early-stage project.
Due to this rapid development pace and short history, unexpected bugs or changes are possible, and additional security vulnerabilities could be discovered.
Nobody can predict what serious problems might occur, so I think we need to be careful, very careful. Especially when applying to production environments, we need to be even more cautious.
But Why Did I Adopt It Despite the Risks?
You might ask: why did you adopt it at your company if you should be so careful?
Honestly, that’s a fair question. There are risks since it’s an early-stage tool.
To be completely honest, our company went from a 5-person development team to just 1 frontend and 1 backend developer due to financial difficulties.
I became the sole remaining backend developer, and that meant I had way more work than expected.
Also, being a startup, the company decided to actively adopt AI as a more economical option than hiring new people.
So I hope you’ll understand.
Closing: The Future of Developers
What I felt through this project is that AI is evolving from a “helping tool” to a “delegate-able colleague”.
Previously, I asked AI questions and received answers. Now I give AI tasks and receive results—in a code-reviewable form (PR). I can feel the scope of what AI can do expanding.
To be honest, even while building this automation, I keep thinking: What happens to junior developers like me if AI advances this far?
Right now, I’m using AI to boost my productivity, but couldn’t companies decide that AI alone is sufficient? Since AI can write code, and only a handful of senior developers are needed for reviews and decision-making.
It’s scary, but I feel I have no choice but to ride this wave. Resisting AI feels like falling behind. That’s why I’m actively trying to adopt it.
I want to believe that the path to survival is not competing with AI, but becoming a developer who uses AI well.
Thank you for reading this long post.
References
OpenClaw
- OpenClaw GitHub
- OpenClaw Organization
- OpenClaw Documentation
- OpenClaw Security Documentation
- The creator of Clawd: “I ship code I don’t read” - Pragmatic Engineer
- Who is OpenClaw Anyway? - SuperSeed
- OpenClaw: How a Weekend Project Became an Open-Source AI Sensation
Security
- From Clawdbot to OpenClaw: When Automation Becomes a Digital Backdoor - Vectra
- OpenClaw Bug Enables One-Click Remote Code Execution - The Hacker News
- Researchers Find 341 Malicious ClawHub Skills - The Hacker News
- OpenClaw surge exposes thousands, prompts swift security overhaul - AI CERTs
- How to secure OpenClaw: Docker hardening, credential isolation - Composio
- MCP Security: Risks, Challenges, and How to Mitigate - Docker
- OpenClaw Sovereign AI Security Manifest - Penligent