Surviving as a Non-CS Developer: A 3-Year Retrospective
Hello. I’m Jeongil Jeong, a backend developer with three years of experience, currently working at a proptech startup.
Thinking of people wondering whether to start development as a non-CS major, I’ve put together how I got here, in chronological order.
It’s not that I’m out to brag, “Look at me, what a successful case!” It’s closer to a record of someone who survived three years, more or less, on a half-and-half mix of desperation and luck.
Beginnings
2018 · Stepping into the world through sales
My parents had one firm conviction.
“When you graduate from high school, we’ll give you 30 million won and you’ll be on your own. Use it for college, a job, or a business—do whatever you want.”
Without a clear dream, I figured going to college then would only waste money and time. So as soon as I graduated, I did my military service, and right after discharge I jumped into sales. I was twenty-one.
I did sales for about five years. But sales, with its structure where results reset to zero every month, started to leave me a little disillusioned. No matter how well I did one month, the next month started from zero again, and every time I felt what I’d built up disappear, I’d wonder, “Am I actually growing?”
Takeaway — I think I wanted work that kept accumulating, work where I could grow.
2022.07 · Deciding to become a developer
One day I heard my younger brother was preparing to become a developer through a government-funded program, and I looked into the developer profession for the first time. The line “developers have to study for life” struck me—to someone whose work reset every month, that wasn’t a downside but an appeal. After a few days of deliberation, I quit and enrolled in a government-funded academy. I was twenty-five.
The course was eight hours a day, five days a week, for six months. Even with the same education, how people approached it varied a lot. Because it was free, many came in thinking “let me just give it a listen,” while I—responsible for my own living expenses—felt strongly that “this might be my last chance to study something properly.” Of the roughly twenty people in my class, only three or four became developers.
My study method went: learn a concept from a lecture → build a small personal project by hand → and only then truly understand it. On top of that, I joined a study group two or three times a week. If I stopped at just watching lectures, it felt like I only knew it in my head; I felt I internalized something only after building it once with my own hands.

For example, the academy was still managing its library by hand, so I took on a project to build a library-management program that could handle book rentals via barcodes. By building things that were either interesting or seemed genuinely useful, I internalized the concepts.
Takeaway — Honestly, with anything—not just development—if you want it badly enough, I think you learn it that much faster.
My First Company
2023.03 · Landing my first job
From December 2022 to January 2023, as I finished the academy, I began my job search in earnest.
I’d started applying to companies before graduating, but reality differed from the academy’s marketing. I was rejected at the resume stage over and over, and my confidence was at its lowest. Still, polishing my resume and portfolio with each application and sitting through a few interviews, I found startups that valued experience and enthusiasm. And so, about two or three months after I started applying, I became the first in my class to get hired.
The interview was with one CTO and two dev leads, for about an hour. It began with personality-fit questions, but from the middle it turned technical, and as the follow-ups deepened, I hit a point where I couldn’t answer. That’s when the CTO said, “This back-and-forth of questions and answers is a good sign—it means there’s that much more I want to hear from you.” Those words stayed with me even after the interview.
2023 · The day I got badly burned
My first company was a fintech startup of about twenty to thirty people. Since it was my first time doing real development work, there was so much to learn that it was genuinely fun. Wanting to be recognized, I even kept asking my team lead for more work.

Honestly, there wasn’t much about the work itself that I found difficult. If you could handle the usual—Java, Spring, JSON, REST APIs, databases, CI/CD—you could do the job. I lacked domain knowledge, but I figured that was something time would solve. And it did.
When senior developers half-joked, “An ace has joined,” I felt recognized and it genuinely made me happy.
Then, around the end of my probation, I made one big mistake. I failed to notice that the test data on the dev server contained real customer data, and sent test emails to about 600 customers; the operations team got customer-support calls saying users had been inconvenienced.
When the operations team came over to the dev team and asked, “Did you happen to send these emails?”, a chill ran down my spine and I broke into a cold sweat all over. I was genuinely trembling. I thought I’d done real damage to the company, and for a while my hand hesitated every time I pressed a run button.
Takeaway — Accidents don’t come from grand places; they always came from the one check I skipped. Until then, in my hunger to be recognized, I’d been fixated only on processing things fast and in large quantities.
Even now that I’ve left, I still grab a drink now and then with the operations manager who cleaned up after that mess, and we talk about it. He says he really resented me back then… and each time I tell him he truly went through a lot and that I’m nothing but grateful. Haha.
Afterward, the work I took on kept growing. Before I’d been there a year, a junior joined under me and I even came to teach a newcomer; I handled settlement and the back office, and was eventually given full server and DB access. Developing new requirements and cleaning up after incidents, over and over, at some point I caught myself thinking, “I’ve come to know how to do this job.”
2023.12 · Taking on DevOps
While I was hard at work, an event that became a major turning point in my career happened.
In December 2023, the company’s only DevOps engineer was scouted away on better terms, and we faced losing the one person who fully understood our servers. The plan was to hire a successor and run a month of handover, but hiring wasn’t feasible given the company’s situation, and it ended as, “Then I’ll at least leave documentation behind.”
From my standpoint as a developer, this made me deeply uneasy. He was practically the only one who knew the entire server setup, and once he left, there would be no one to respond if something broke.
With no idea when the next DevOps hire would come, I judged that a server problem in the meantime could cause a serious outage for our service.
So, at the risk of overstepping, I went to him separately and said:
“If it’s not too much to ask, could you teach me a little about the company’s infrastructure? During the DevOps gap, if something breaks, someone has to fix it—it’ll be a hassle for you, but if you could teach me even a little, I’ll somehow hold the line with what little knowledge I have.”
That’s what I said to him.
Perhaps he thought well of me for that, because he gave me a month of mentoring and handover. Thanks to him, I got to encounter the concepts behind Kubernetes, AWS EKS, Jenkins, ArgoCD, and ELK. It wasn’t an amount I could absorb in a month, so I remember writing down every keyword he tossed my way in a notebook and studying them one by one. Being a fintech company, the internal and external networks were separated, which made it all the trickier.
In the end, I came to run the infrastructure alone for about seven months until the next DevOps engineer was hired. Looking back, it was a fairly bold thing to take on.

In those seven months there were a few outages I somehow contained, and there were times I couldn’t solve something and reached out privately to the engineer who’d left to ask for an SOS.
Even so, I think this was one of the periods I learned the most in my career. Looking back, it was a great stroke of luck—until then, many companies’ developers didn’t even have access to the infrastructure.
Takeaway — From this point on, being a developer who could also handle infrastructure became a real weapon for me. I could see the service from a wider angle, and I came to understand both the developer’s and the DevOps engineer’s point of view.
2024.01 · Acquisition, and holding on
Rumors that the company was struggling spread, and the dev team shrank from ten to four. My mentor and team lead left, and I became the longest-tenured person on the settlement team. Not long after, the company was acquired by another firm in the same industry, and with fewer people the work only grew. Being a first-year developer single-handedly responsible for a company’s settlement and servers was not easy, even thinking about it now.
2024.03 · Salary negotiation
I waited, believing the acquiring company’s words—“we’ll raise your pay a lot, so please stay”—but the raise fell far short of expectations.
Personally, since I was handling settlement, the back office, new feature development, and infrastructure operations all at once, I wanted that to be recognized in kind, and it stung that it wasn’t reflected.
Management said that between “a raise for me” and “hiring a new DevOps engineer,” it would be hard to go beyond the salary table, so they’d go with hiring DevOps—could I just wait until that hire was made.
2024.07 · Handing over DevOps
A new DevOps engineer joined, and I handed over the infrastructure I’d run for seven months. I shared the trial-and-error and incident-response experience I’d accumulated running it alone. Fortunately they adapted quickly, and after that the infrastructure was operated stably.
2025.01 · Deciding to leave
And so salary-negotiation season came around again.
Management said that with the company struggling, they “couldn’t give a definite answer on whether they’d negotiate at all this year, and if so, when.” In a meeting I asked several times, “If you can, say you can; if you can’t, say so clearly,” but the answer stayed the same.
Takeaway — Rather than clinging to a vague hope, I judged that when there’s no clear answer, the right move is to act.
In February 2025 I was accepted at my current company, finished a month of handover, and moved in March.
After I gave notice, there were several rounds of meetings. They repeatedly offered conveniences—saying that while financial negotiation was hard given the company’s situation, they could let me work remotely if I wanted—but
my heart had already left, and I’d received an offer raising my total compensation by more than 10 million won, so honestly the offered conveniences didn’t land with much weight.
In the end, in August 2025, that company laid off the entire dev team without any salary negotiations, and everyone left.
My Second Company
2025.03 · The move

The new company was a proptech platform connecting people looking to buy or sell homes—apartments, officetels—with licensed real-estate agents. It was at the pre-Series A stage, around fifteen people, with just two backend developers: the CTO and me.
The team happened to be mid-migration from a legacy monolith to MSA. So my first impression was, “There’s going to be a lot to do.” Sixteen split-up repos, an MSA excessive for the scale, a monolithic service still sitting in an IDC, no proper monitoring system, and services all crammed onto a single instance.
Because it carried quite a lot of technical debt, I figured there’d be plenty to do, which actually made it interesting to me.
2025.04 · Starting with documentation, then MSA
The very first thing I did after joining was documentation. There was no onboarding doc when I joined, so I documented things by asking the CTO directly about whatever I was curious about. Drawing out the system architecture, I came to understand the service’s structure and flow.


The CTO said he was both grateful and a little sorry that my first contribution to the company was documentation. The onboarding doc was organized in the company’s internal Confluence, set up so that developers who joined later could refer to it.
After that I took part in migrating legacy services to MSA, and trying to split out the core ‘apartment’ domain into MSA led to something I had to think hard about. Apartment and matching shared the same tables and were deeply entangled, so I couldn’t peel just one of them off.
Takeaway — Having only built MSA in side projects before, actually operating and developing it in a real service made its pros and cons much clearer. In my own judgment, MSA was excessive for our service, so later (January 2026) I merged the MSA services into a modular monolith.
2025.06 · Kubernetes and monitoring
At this point the company’s services were set up with all the MSA containers running on a single instance. As services grew, they kept dying from memory shortages, or one service would hog the CPU and slow down the ones next to it. On top of that, the company hadn’t even had a dev server, so testing had been done in production. (I was quite shocked by this—I’d assumed a dev environment was a given.) Starting in June, I moved to Kubernetes (GKE), stripped out Eureka and the gateway, and set up GitOps with ArgoCD.
And what I cared about most was monitoring. Until then, the dev team couldn’t detect a system failure first. Judging CloudWatch alone insufficient, I built a monitoring stack myself with Loki, Grafana, Tempo, and Prometheus.
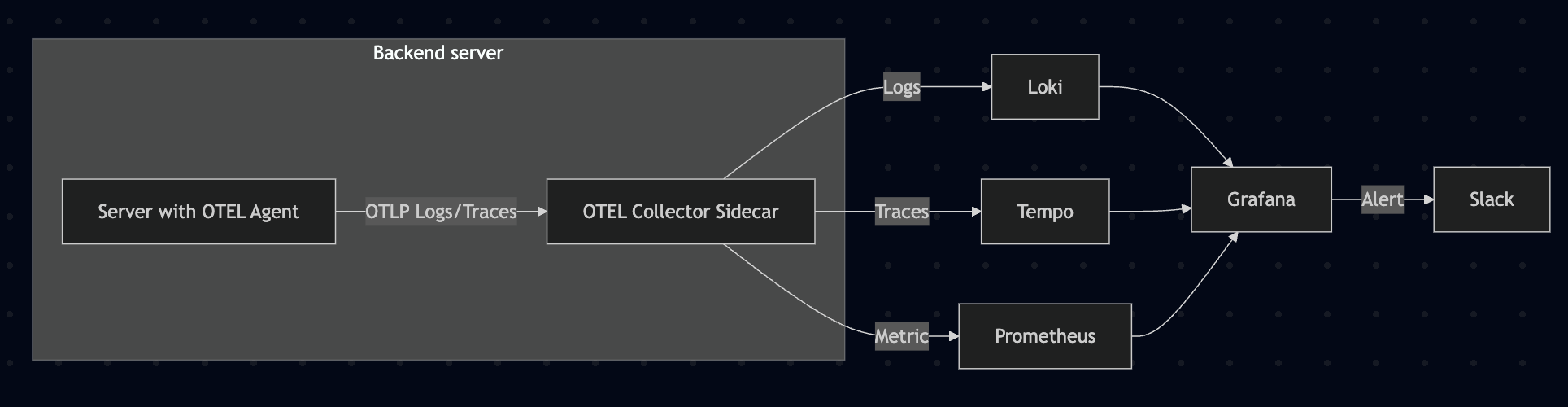
Thanks to it, failure detection dropped from hours to minutes. We actually started catching problems like an exception that had been firing because naming conventions weren’t followed.
2025.06 · The investment falls through
I’d joined after hearing in the interview that “the Series A is all but confirmed,” but before I’d even been there three months, I heard that investment had fallen apart.
This shook me quite a bit. I’d misread “all but confirmed” as “the investment is confirmed,” and assumed that money would stabilize the company. Only afterward did I learn that even with a signed contract, nothing is certain until the money is in. (As it turned out, the contract hadn’t even been signed. Haha…)
Takeaway — “The investment is all but confirmed” != “We got the investment.” Please keep this line in mind.
I did hear that the failed investment had worsened the company’s cash flow, but I decided to hold on for a year, as long as my paycheck wasn’t late.
Besides, I’d joined partly because I saw the company’s potential, so even though this round of investment had fallen through, I still believed in that potential and strongly wanted to contribute everything I could to the company.
2025.08 · Left on my own
But the fallout of the failed investment came back as people. From August to October, starting with the CTO, colleagues left one after another, and somehow, before I’d even been there six months, I came to be solely responsible for the backend and servers of a platform with 20,000 MAU.
When the CTO’s departure was decided, the CEO—carrying some anxiety—asked me, “Hiring is hard right now; can you really handle both running and developing the service as the only backend developer?”
The excitement of a new environment hadn’t even worn off, so honestly I felt lost. But having spent five months getting a fair grasp of the system, my conclusion was “it’s doable.”
When I answered, “It won’t be easy, but it’s not impossible,” the CEO said, “For now just maintaining the status quo is fine—please just keep the service running stably.”
From then on, for a while, it became a time of just surviving. Strangely, though, once I was on my own, the things that needed fixing came into sharper focus.
I have to look after this whole system alone? With that thought, I figured if I was going to manage it solo, I had to start with these things first. So I set priorities and decided to fix, one by one, the parts that were management bottlenecks.
2025.09 · Consolidating into a monorepo
The first thing that caught my eye was code duplication. Managing 16 repos in an MSA setup meant that fixing one shared Exception required repeating the same change across 16 repos.
So, to make it manageable, I merged the 16 repos into a single monorepo (multi-module). I consolidated everything while preserving commit history with Git Subtree, and as a result the build time dropped from 27 minutes to 8, and about 5,500 lines of duplicate code disappeared. (In exchange, it produced a 230,000-line PR.)
This was work I’d started back in April but hurriedly wrapped up, all at once, in August and September.
2025.09 · Negotiating after proving it
After showing for a month that I could keep the service stable on my own, I requested a meeting with the CEO and negotiated my salary. As a result, we agreed I’d receive a satisfactory raise starting in November.
2025.10 · Buried in stabilization
After moving the servers to Kubernetes, I noticed the first request after every deploy was slow. The first response, usually 100–200ms, spiked to 1.2 seconds right after a deploy, so I tackled the JVM Cold Start problem;
and I fixed a case where, during the MSA migration, changing one column from bigint to varchar made a query 8x slower;
and when the free tier of GitHub Actions (2,000 minutes/month) hit its limit, I patched it by attaching a Self-hosted Runner on a teammate’s MacBook, then put Jenkins on Kubernetes so pods spun up only when needed—pouring myself into stabilizing the service.
2025.12 · Did we really need MSA?
At year’s end, I started putting a question to myself. Running 13-plus services in a distributed setup on my own while also building features meant far too many bottlenecks, and MSA was excessive in both cost and complexity for the company’s scale. With the GCP startup credits running out in April 2026, there was a cost-cutting need too—so I decided to seriously reconsider whether MSA was necessary.
Reflecting on what I’d felt while doing MSA, I even wrote an MSA series, including a piece titled Did we really need MSA?.
Takeaway — I wrote about the upsides of MSA I felt in that post in detail, but to put it briefly: MSA is a choice to take on complexity in order to solve a particular problem. Choosing MSA when no such problem has even arisen is choosing complexity for no reason. MSA is a means to solve a problem, not an end in itself.
2026.01 · Rolling back to a modular monolith
So I merged 11 services into a single application. I left only notification and batch as independent services, and abstracted inter-module calls behind a ModuleApi interface. As a result, pods went from 26-plus to two or three, Compute cost dropped from 96,505 won/day to 58,768 won (about 1.13 million won/month saved), and complexity fell sharply.

Before, when something broke, I had to dig through several SQS queues and the logs of several services; now I can check all the logs in one service. Working alone, hunting through many services to find a problem had been anything but easy, but now that it’s traceable from one service’s stack trace, problem-solving got much faster.
Takeaway — I felt again how important it is to choose based on your team’s and service’s situation.
2026.02 · Launching new AI features
Around this time I started weaving AI into the service.
The company already had an LLM-based service built on a fixed RAG pipeline,
but the new feature being planned needed to handle natural-language property recommendations like “recommend a newly built apartment near Songdo or Gangnam Station, ~100㎡ (30 pyeong), under 1 billion won, 500+ units.”
So I redesigned it so the LLM only makes the plan and code does the execution, and launched the new ‘AI Property Recommendation’ feature.

I also developed and launched an ‘AI Title-Deed Analysis’ feature that assesses jeonse (lease) fraud risk.
2026.05 · Turning reliability into a “promise”
The most recent thing I worked on was SRE. Checking exception logs alone, as “ERROR!!! Please check” alerts kept firing while things were actually fine, at some point I stopped checking the alerts. And I had no objective basis to judge “is it okay to deploy right now?”
So I set the 5xx rate as an SLI and quantified reliability with an Error Budget—99.9% (about 43 minutes of allowed failure over 30 days). One more thing I learned: a 200 OK isn’t always healthy. The actual-transaction-price batch had stopped and was serving month-old data, yet the API kept responding 200. So I also added synthetic monitoring that checks even data freshness.
Takeaway — Reliability should be a “promise,” not a “gut feeling.”
2026.06 · Where the company stands now
The company still hasn’t secured investment. I don’t know whether it’ll somehow survive or go under, but I’m doing my best to fulfill my role.
Of course there are days my motivation flags, but I hold on with the thought, “Whether this company sinks or swims, I’ll do my part.”
Three Years In
I’ve now passed my third full year. Four years ago I was someone who didn’t even properly understand System.out.println("Hello World"); now I spend my days handling both backend and infrastructure and taking responsibility for the service’s stability.
Looking back, I think being a non-CS major is a clear disadvantage in the market. So I accepted that my starting line was behind everyone else’s, and I believe it’s important to build strengths elsewhere to make up for it. Building things by hand instead of stopping at lectures, and taking on the empty seats like infrastructure—those, too, were choices that came from trying harder precisely because I knew I was lacking.
The hardest thing to bear back in my sales days was the feeling of returning to zero every month; in development, what got stuck yesterday becomes the foundation for today. I’m still full of things I don’t know, but just being able to build up a little each day makes for days I’m grateful for.
If someone wondering whether to start development as a non-CS major has read this far, I hope you’ll take it simply as: there’s a person like this living his life as a developer too. Thank you for reading this long piece.