[Troubleshooting] Failed Graceful Shutdown During Kubernetes Pod Scale In, Journey to Find Lost Async Logic
I’m sharing about a failed Graceful Shutdown issue I encountered at work.
Problem Occurrence
Usually, I encounter exceptions and problem situations through Slack quite often. Today, I encountered a problem differently than usual. This problem started with a back office user’s inquiry.
“I think one piece of data doesn’t match…!”
I immediately rushed to check the data.
Upon checking, one of the Flag columns indicating the status of each tuple in a specific table was in a different state than expected.
Fortunately, it wasn’t a Flag with enough impact on the service to require urgent resolution.
However, we naturally needed to accurately analyze why the Flag column was different from the expected value.
A developer in charge of that server said they would check it, and I was ready to hear what the reason was, but as they were diligently searching for the cause, they told me.
The Request that threw a request containing logic to update that Flag column returned a Response normally, but I don’t know why the Update didn’t happen…? What is this???
Thus… the Debug journey began.
| |
The logic where the Flag column is updated was as follows.
Actually, it’s nothing special when you look at it like this. That’s why I was even more confused at first.
This returned Response normally but why would only the Flag column not be updated…? Why?
I was frantically searching through logs thinking about the cause, and suddenly something came to mind.
Those who got a hint from the title might have already noticed, but I wasn’t even thinking about it at that time, so it took some time to find it.
The train of thought was like this:
1. Did the logic die while running?
2. What would cause the server to die?
3. It must be Kubernetes HPA
4. But it's configured to Graceful Shutdown when killing a Pod, right?
5. Did Graceful Shutdown not work properly? Why didn't it work?
6. Ah, async...!What is Kubernetes HPA
HPA (HorizontalPodAutoscaler) has the function to automatically scale out (not increasing Pod resources, but increasing the number of Pods themselves) when resources such as CPU and Memory exceed set thresholds. The HPA controller checks resources and increases or decreases Pods according to the set number of replicas. Source: https://nirsa.tistory.com/187 [Nirsa:Tistory]
What is Graceful Shutdown
When translated literally as “elegant termination,” it feels awkward, but thinking about the opposite case, it seems like a quite fitting expression. Graceful shutdown means handling logic as much as possible without side effects when a program terminates. Source: https://csj000714.tistory.com/518
Root Cause Analysis
When Kubernetes HPA thinks a Pod is no longer needed and sends a Delete, it sends a SIGTERM signal to the container within the Pod before deleting it.
After sending the signal, it waits for a certain period of time (30 seconds by default), and if the container doesn’t terminate within that time, kubelet sends a SIGKILL signal to forcefully terminate the container.
Spring Boot’s built-in WAS Tomcat supports Graceful shutdown when the option is set,
and since that server was properly configured, when receiving SIGTERM, it completes the requests it received, returns Responses, and then terminates the server.
So I thought that since this method called async logic and then returned a Response, Tomcat thought it was finished normally and terminated.
I immediately checked the logs focusing on when the Pod died.
As expected, correct answer.
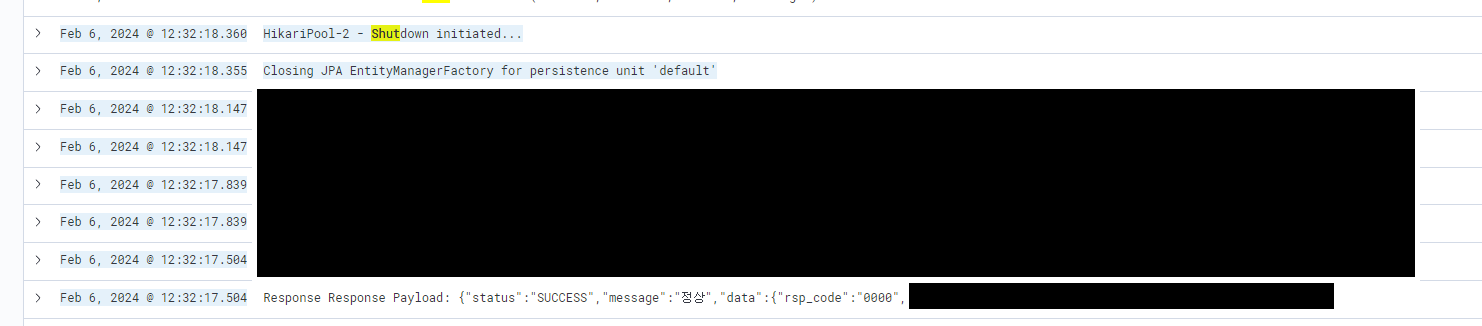
You could see that the server started Shutting down immediately after the Response.
The Spring application terminated even though it hadn’t completed executing the async logic.
Then I searched for related issues and was able to find a similar case.
I was able to find a solution as well. I also solved it in the following way. (Related article)
Summary
In a sequence diagram, it was as follows.
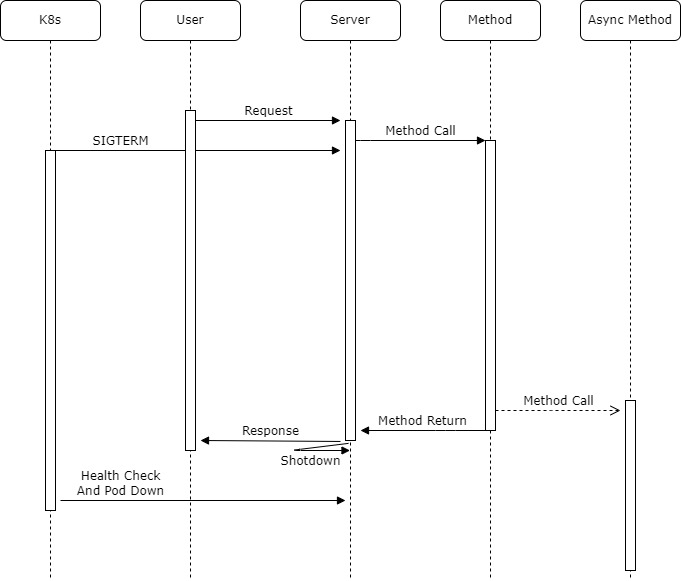
Summarizing in text, it was like this:
- Request at 12:30
- k8s pod delete immediately after Request
- That pod no longer receives requests
- Since spring graceful is configured, it waits for shutdown until Response is given
- When it encounters Async logic while running, it throws async and gives response
- Shutdown because response was given
- Async logic doesn't run (problem situation occurs)It was an interesting troubleshooting. It became an opportunity to look at Graceful shutdown in more detail once again, and it was a troubleshooting that made me think more carefully about Health Check and asynchronous processing. Recently, I’ve been looking at infrastructure a lot, and I thought if I hadn’t considered that K8s pods autoscale, debugging might have taken more time.
The above content may contain inaccurate information. As a first-year backend developer, I’m aware that I’m quite lacking, so I’m worried that the information I’ve written may not be accurate. My information may be incorrect, so please use it for reference only and I recommend looking into the related content yourself. If there’s any incorrect information or if you’d like to comment on anything, please feel free to write! I’ll accept it and strive to improve!!!
Reference
https://leehosu.github.io/kubernetes-delete-pod https://hudi.blog/springboot-graceful-shutdown/ https://velog.io/@dongvelop/Springboot-Graceful-Shutdown https://findmypiece.tistory.com/321 https://velog.io/@byeongju/%EB%B9%84%EB%8F%99%EA%B8%B0-ThreadPool%EC%9D%98-Thread%EA%B0%80-%EC%8B%A4%ED%96%89%EC%A4%91%EC%9D%B8%EB%8D%B0-JVM%EC%9D%B4-%EC%A2%85%EB%A3%8C%EB%90%9C%EB%8B%A4%EB%A9%B4 https://peterica.tistory.com/184 https://kth990303.tistory.com/464 https://saramin.github.io/2022-05-17-kubernetes-autoscaling/