Money Disappeared? Transitioning Account Balance Verification Batch from Tasklet to Chunk & Partitioning
Hello. I’m Jeong Jeongil, a 2-year backend developer working at a lending and investment platform.
While internally verifying data consistency in our operational company service, we experienced account balance and internal Point inconsistencies due to transaction processing time and batch work inefficiency, causing verification failures or incorrect notifications.
This post shares my experience introducing Chunk-based processing and Partitioning techniques to solve problems that occurred in the existing Tasklet-based batch processing approach.
1. Background
Our company is an online investment-linked financial platform. Currently, we operate deposit trust management through Shinhan Bank for safe fund management. Let me draw a simple diagram of our company’s fund flow.
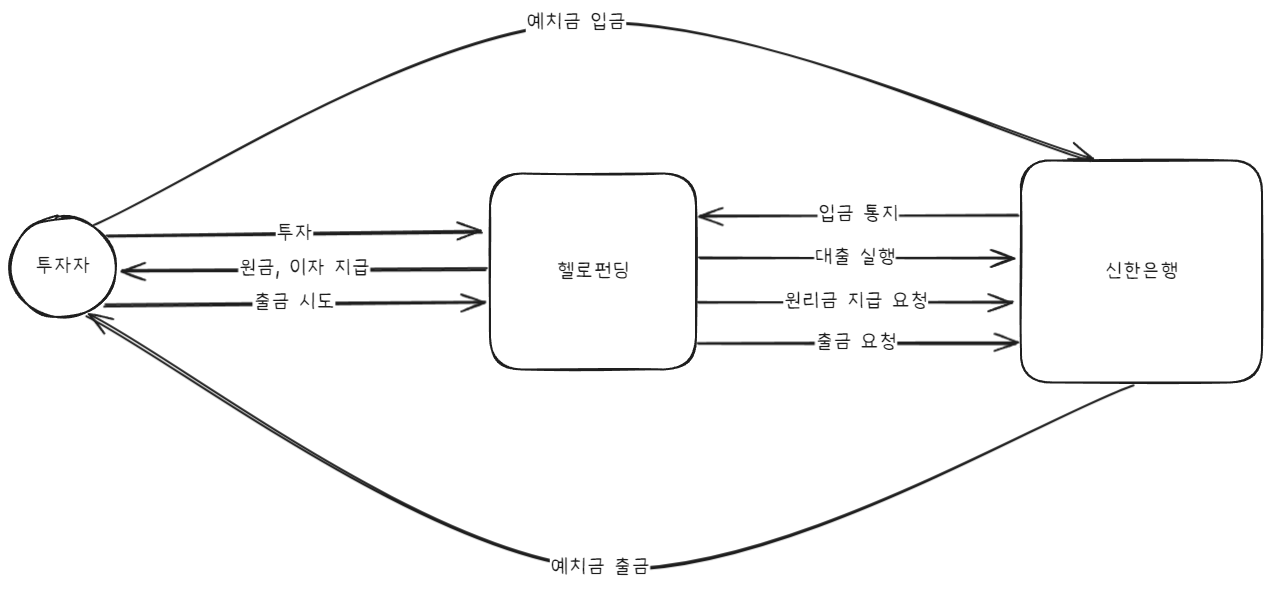
Of course, there are other fund flows besides what’s shown in the diagram, but they’re unrelated to understanding the current problem, so I’ve omitted them.
The most important point in understanding the problem from the diagram above is that actual funds are managed by Shinhan Bank.
If an investor deposits 10,000 won to Shinhan Bank’s virtual account, the actual deposited 10,000 won is managed by Shinhan Bank, and only the fact that 10,000 won was deposited is notified to our company.
We also manage user balance data separately from Shinhan Bank internally and verify consistency. We call the user balance we manage Point.
In this post, I’ll use the following terminology:
- Account Balance: Shinhan Bank deposits
- Point: Deposits managed by our company
Then, cases where data consistency between Account Balance and Point becomes inconsistent can occur. Examples include:
When investor A deposits but it’s not reflected in Point due to issues between the bank and our service’s deposit notification
When principal and interest payment requests lead to Shinhan Bank depositing to investor virtual accounts but not reflected in Point
When Point is deducted after an investor invests but the actual loan isn’t executed, so Account Balance isn’t deducted
Of course, since this is extremely important data related to money, there are numerous defensive logics to solve data consistency problems. Therefore, I can say that consistency breakage is extremely rare.
What I wanted to explain was that gaps can occur between actual Account Balance and Point. Having explained this background, let’s move on to the problem situation.
2. Problem Situation
As mentioned above, since Account Balance and Point are extremely important money-related data, in addition to numerous defensive logics, a batch runs once a day to verify data, checking if differences exist between users’ Account Balance and Point deposits. If differences exist between Account Balance and Point, the batch stores and notifies administrators of the list.
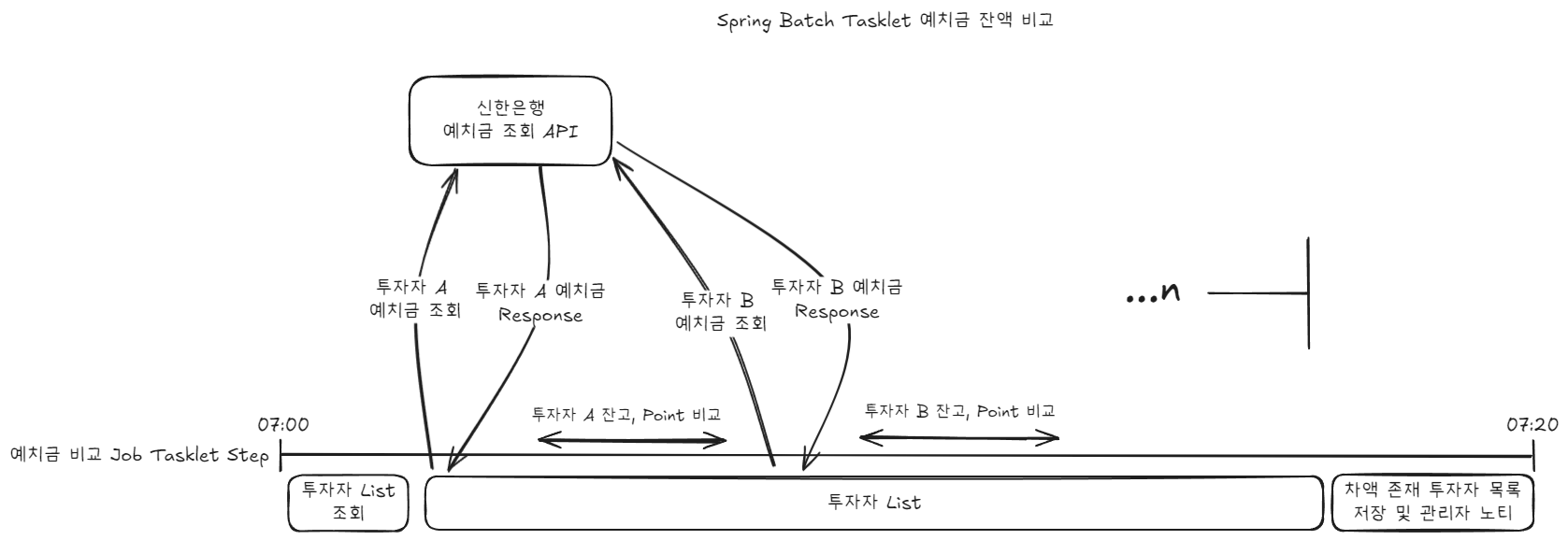
This is the deposit comparison Job that operated in the existing Tasklet method. Looking at the above diagram alone, we can mention several problems.
Although investor balances have no dependencies on each other, they operate synchronously and blockingly. As a result, this Job ultimately consumes more Batch resources than necessary.
Both difference comparison and handling comparison results are done within one step. Having multiple responsibilities in one Step reduces readability and maintainability.
Besides the problems mentioned above, there was one more most important problem, and I was able to convince the administrator to proceed with refactoring based on this reason.
Because Tasklet operated as one Transaction until the Step ended, data consistency mismatches occurred during deposit comparison. Specifically, in the following case:
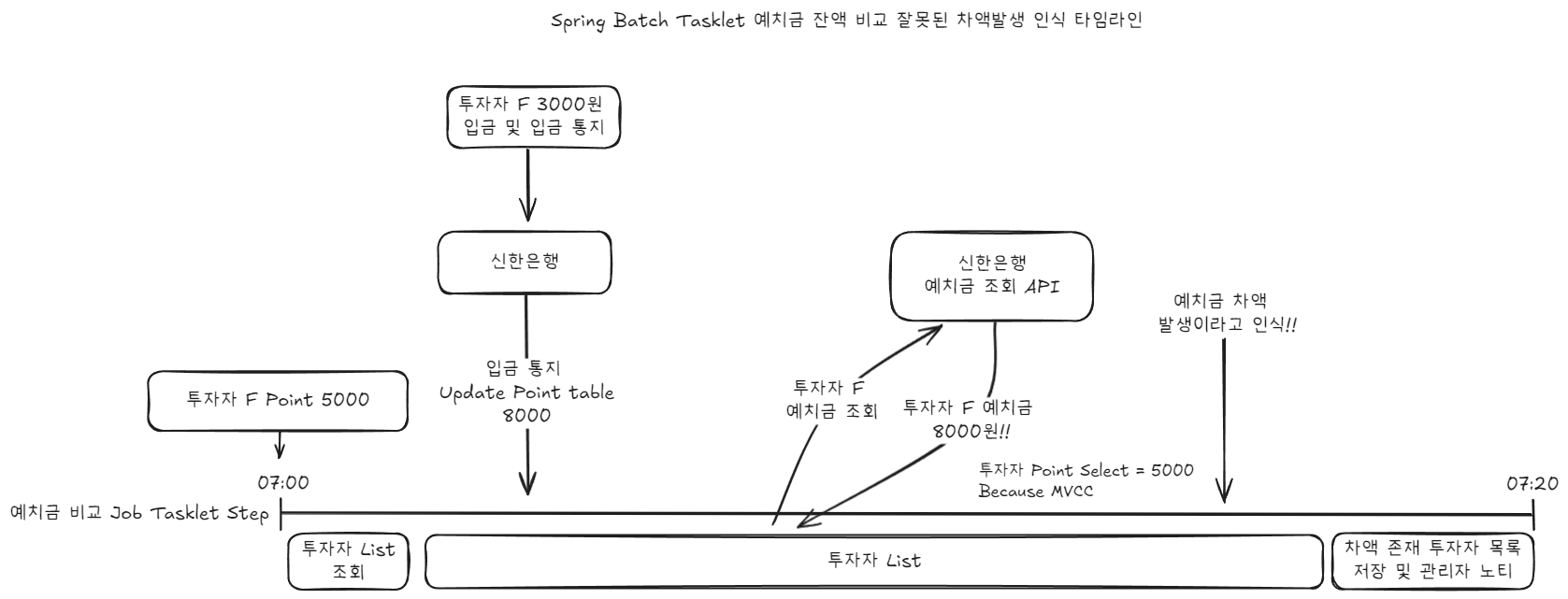
If the Transaction started at 7:00 and a deposit notification occurred around 7:10, cases where that point couldn’t be read occurred.
We were using MySQL as our DB, and MySQL’s default isolation level is REPEATABLE READ, so it operated with MVCC and read data from the snapshot at the transaction start time.
(The comparison logic needs data from multiple tables besides Point. ex) scheduled repayment amount, pending investment amount, scheduled payment amount, etc. In the example, only the Point table was used.)
Fortunately, since the administrators receiving notifications are internal users (company employees), they check current data in the back-office after receiving notifications and confirm there are no data consistency problems with Account Balance. However, from the administrator’s perspective, unnecessary work increases, and from a development perspective, sending notifications with incorrect data is wrong.
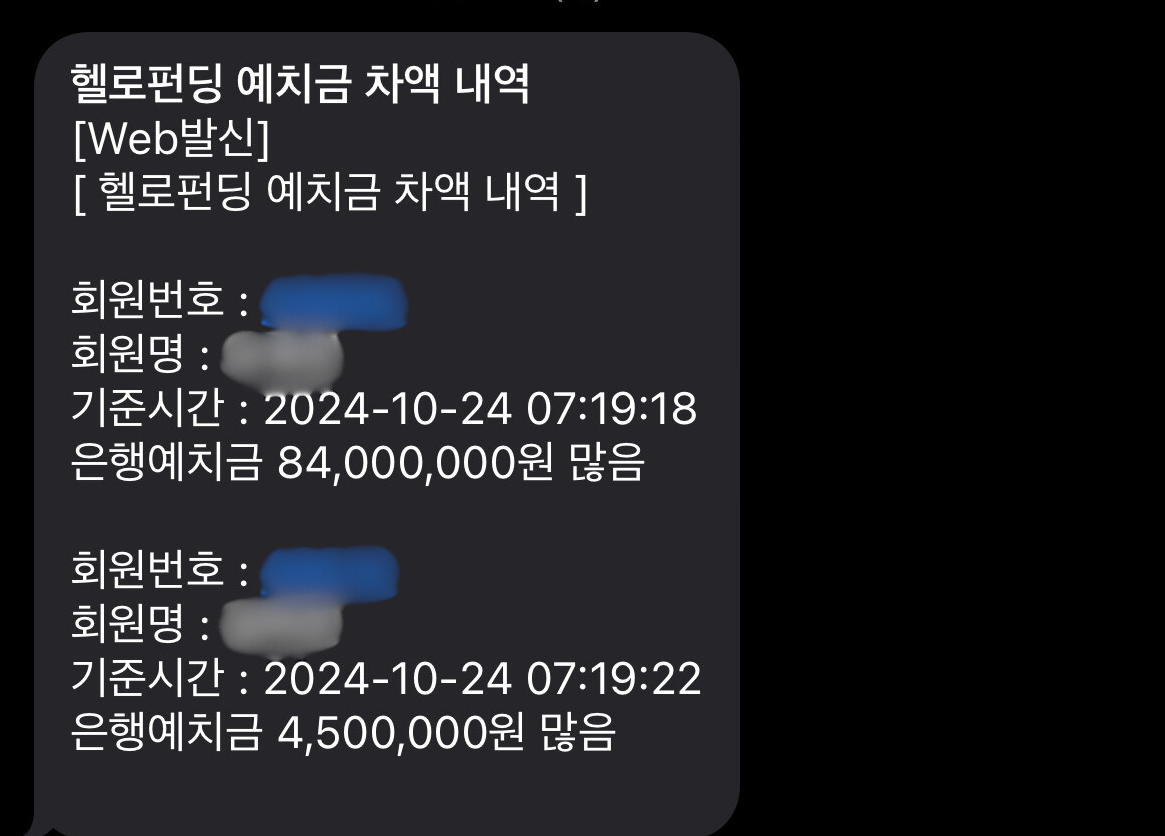
3. Solution: Transition to Chunk and Partitioning
The batch work implemented in the existing Tasklet method had a problem of not reflecting changed data until the transaction ended since all work was processed within one transaction. Particularly, if the batch work started at 7:00 and a deposit notification occurred at 7:10, that data wasn’t reflected in the batch results.
Moreover, performing both comparison work and notification processing logic within one transaction caused structural problems where batch work time lengthened and required reworking from the beginning upon failure. To solve this, I set three goals:
Minimize Transaction Units Improve data consistency by separating transactions into as short units as possible.
Separation of Responsibilities Separate data verification and notification processing logic to improve code readability and maintainability.
Introduce Parallel Processing Optimize work speed by utilizing the characteristic that data has no dependencies.
Transition to Chunk-based Processing
The biggest change when transitioning from Tasklet to Chunk method was that transaction units became smaller. Previously, since one transaction encompassed the entire work, data changed during work wasn’t reflected. By dividing into Chunks and processing, I designed each Chunk to commit transactions independently.
- Chunk Processing Method
- Reader: Reads data from the database according to the set Chunk size.
- Processor: Performs work comparing or processing data read by Reader.
- Writer: Performs subsequent work storing processed data or sending notifications.
The biggest advantage of the Chunk method is being able to limit transaction scope. This allowed changed data to be reflected even during batch execution, and enabled reprocessing only specific Chunks when errors occurred.
Introducing Parallel Processing through Partitioning
Although data consistency improved with Chunk-based processing, the problem of consuming more server resources than necessary remained since it still operated in a blocking manner within each Chunk size.
Since there are no dependencies between investor balance and Point data, there was no need to operate in a blocking manner.
To compensate for this, I applied the Partitioning technique. I improved speed by dividing data into multiple Partitions and processing them in parallel.
- Partitioning Application Method
- Divide data by GridSize and allocate independently to each Partition.
- Each Partition is processed with independent transactions.
- Manage using Spring Batch’s
PartitionHandler.
Implementing QuerydslItemReader for Dynamic Data Querying in Partitioning
When using Partitioning, you can perform parallel processing by dividing data into predefined Partition units. Generally, the Partitioner divides data by GridSize in advance and distributes to each Partition, and each Partition processes its allocated data.
However, if you divide Partitions into fixed sizes in advance, even though each partition thread’s end time differs significantly, idle threads don’t process additional data, so total processing time increases.
Our team solved this by making all Partitions’ Readers share the current query point in a thread-safe manner, so partitions that finish writer work first can be allocated the next task.
QuerydslPagingItemReader Implementation Code Example
| |
startDate,endDate: Parameters dynamically provided during batch execution.
| |
Why Did I Choose QuerydslPagingItemReader?
Since our company has been implementing complex queries based on QueryDSL, I wanted to maintain consistency.
I also used it for type verification at compile time.
Architecture After Refactoring
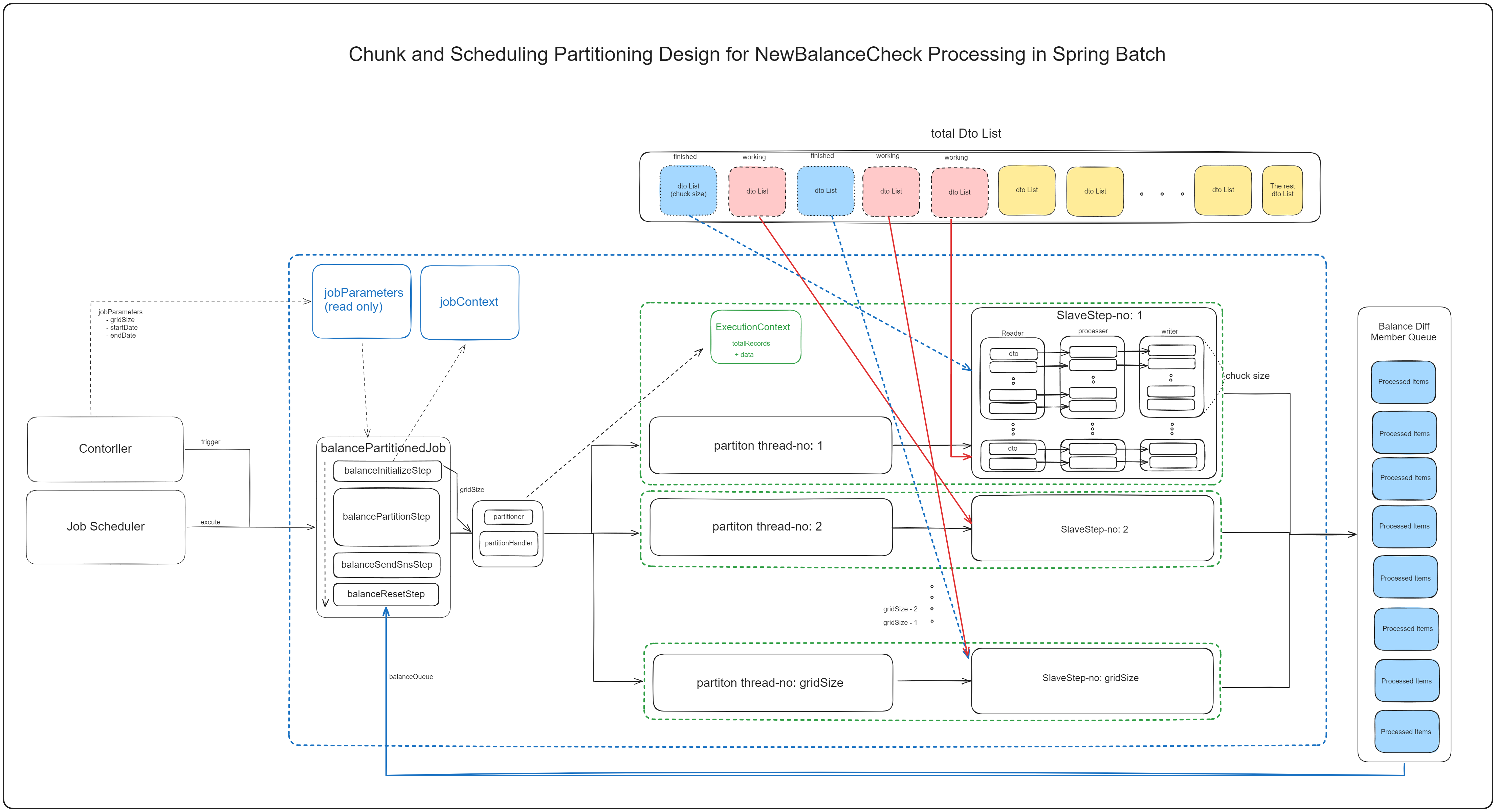
Improvements
By introducing a Querydsl-based Reader, I think more flexible and efficient batch work became possible as the Reader dynamically queries data.
I improved maintainability and readability by separating Steps according to each responsibility. Each Step has the following responsibilities:
- balanceInitializeStep: Initialization work for Partitioning
- balancePartitionStep: Parallel deposit comparison work using Partitioning
- balanceSendSnsStep: Administrator notification for targets with difference occurrence during deposit comparison
- balanceResetStep: Data initialization work after completing all previous steps
And we implemented by separating the transactions of Reader, Processor, and Writer to minimize transaction units.
Generally, Reader, Processor, and Writer are transactionally bound in chunk units, but since Account Balance data itself is managed by Shinhan Bank, we thought there was no meaning in binding Reader, Processor, and Writer transactions in chunk units.
Results and Improvements
1. Enhanced Data Consistency By minimizing transaction units, the probability of data consistency problems significantly decreased. Deposit notifications and other changes occurring during work could be reflected almost in real-time.
- Maximum Transaction Processing Time Before: About 22 minutes → After: Reduced to 0.01 second level. (Data consistency problem occurrence probability: 1/132,000)
2. Processing Speed and Resource Efficiency
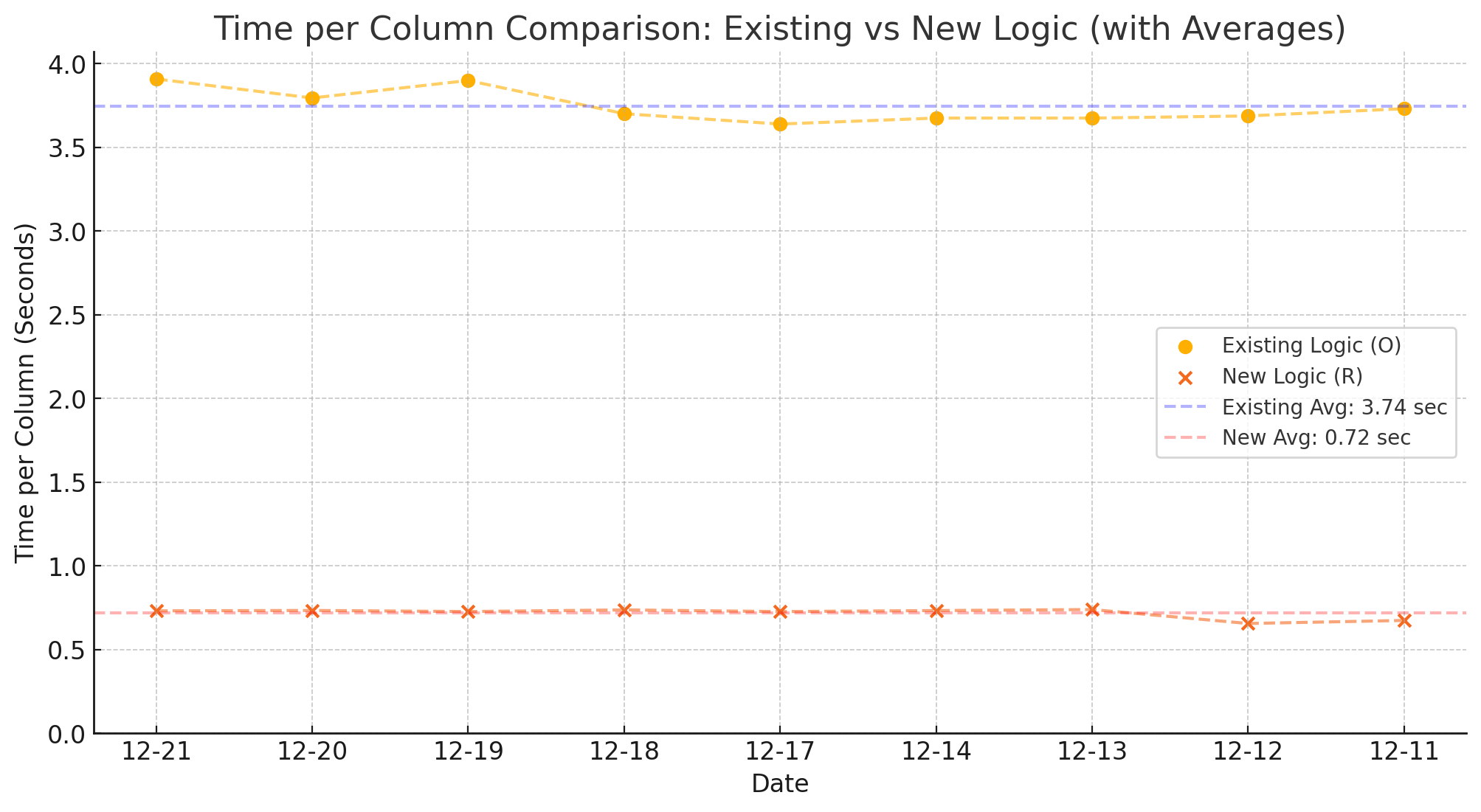
- Processing Time per Row Before: 3.74 seconds → After: 0.72 seconds (80% reduction).
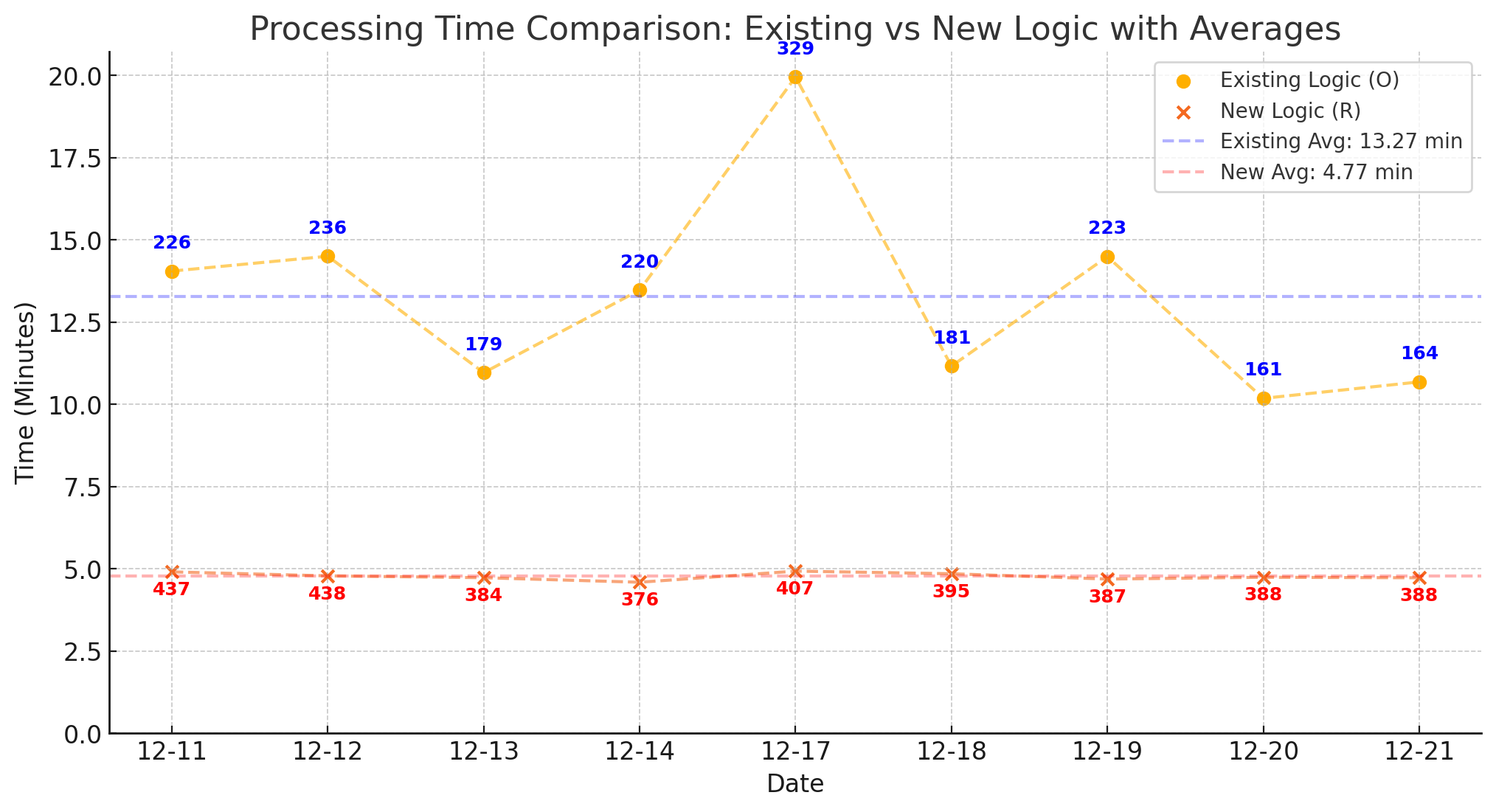
- Average Duration Before Tasklet method: 13.27 minutes → Chunk/Partitioning method: 4.77 minutes (64% reduction).
Concerns and Trial and Error During Development
Thread Management and Parallel Processing
I found optimal settings by comparing and testing SimpleAsyncTaskExecutor and ThreadPoolTaskExecutor for parallel processing. I explored the appropriate number of threads by comparing speeds according to thread pool size.
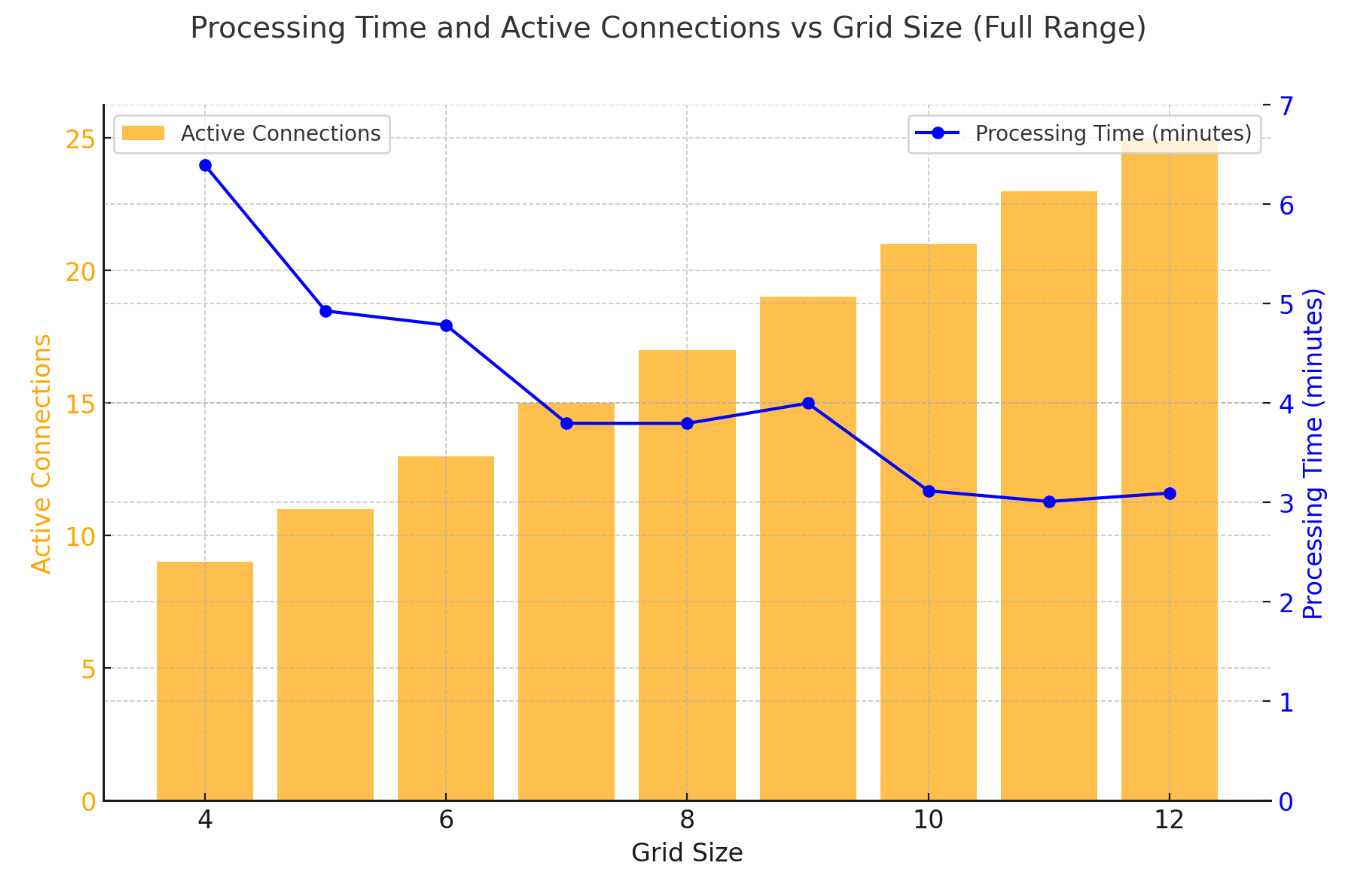 Based on such test results, I fixed gridSize and thread count to 10.
Based on such test results, I fixed gridSize and thread count to 10.
When Just Closing EntityManager Without Committing Transaction
During testing, when I closed the entityManager in the Reader without closing the transaction, I faced a HikariCP Deadlock problem. I thought the transaction would be committed when the entityManager closed, but it wasn’t, which was confusing. Thinking about it, it was natural.
This problem was solved by closing the transaction and then closing the entityManager.
Role Separation Among Reader, Processor, Writer, Listener
One of the most concerning parts during logic separation was designing so that roles between Processor and Writer wouldn’t overlap. After pondering how to safely pass the list of members to notify to the next Step, I implemented thread-safe data sharing using ConcurrentLinkedQueue.
Also, in the early implementation, initialize work or cleanup work was implemented in Listeners. Since this part didn’t match the class’s role, I separated and implemented them as separate Steps.
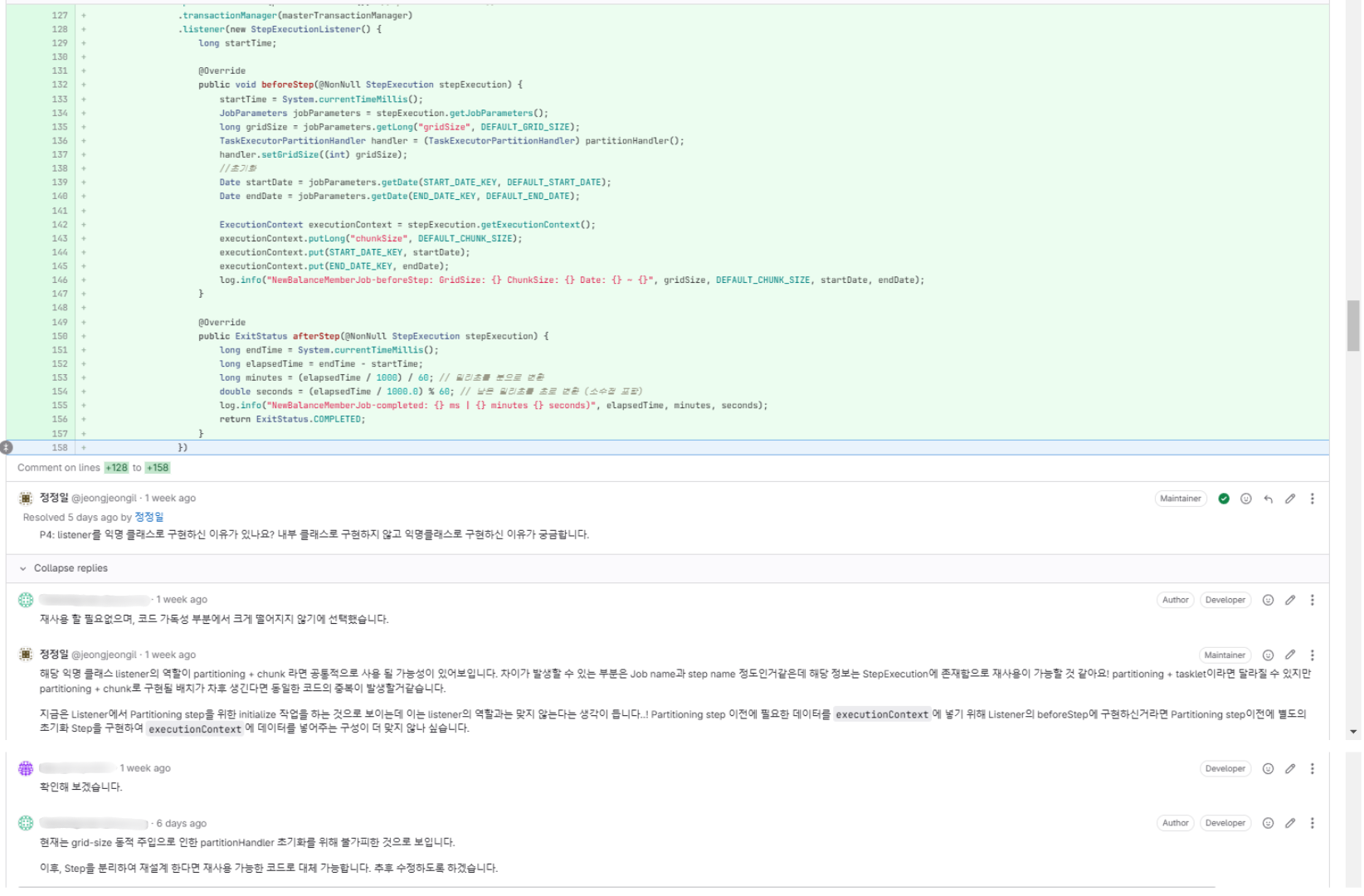
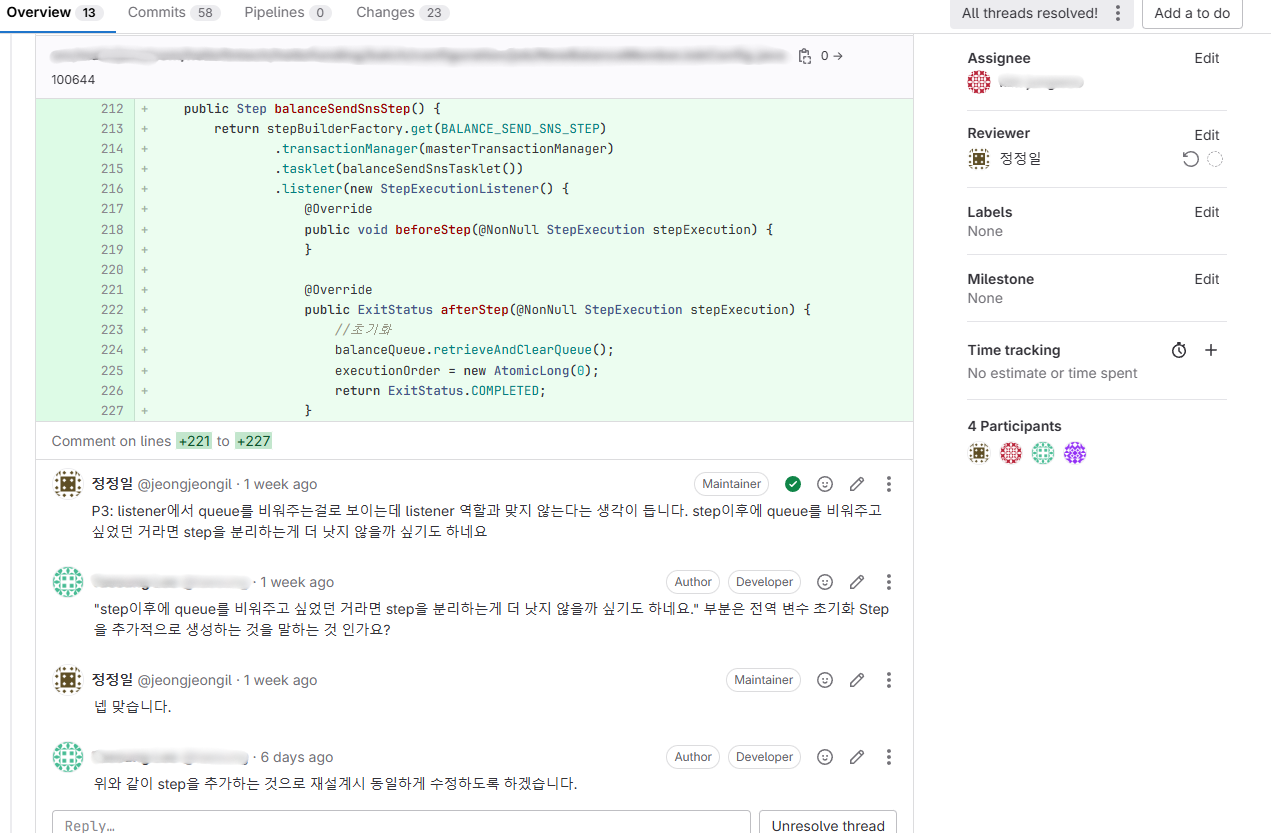
(After this code review, we coordinated improvements through scrum and made corrections!)
Closing Thoughts
For me, the challenge started from the process of persuading my team leader by advocating that problem-solving through introducing Chunk and Partitioning was possible. Fortunately, my team leader also empathized with the necessity, and our team could proceed with it.
This refactoring project was an important experience not just in reducing exception occurrence probability and improving performance, but in securing maintainability and reusability by restructuring the code structure.
Particularly, designing efficient batches by maximizing the advantages of Chunk and Partitioning techniques seems like it can be a good precedent applicable to other batch works in the future.
I think it was a time when I could significantly increase my understanding of Spring Batch through various experiences.
In this refactoring, I didn’t actually handle the implementation. I was responsible for proposing Chunk and Partitioning introduction, participant decision, schedule coordination, scrum management, technology adoption decision, code review, etc., and participated in architecture design, troubleshooting, and implementation direction setting.
I’d like to express my gratitude to Taesung and Byungwook from our team who handled the most important Chunk and Partitioning method implementation and testing, and I’ll conclude this post here.
Reference
https://techblog.woowahan.com/2662/ https://jojoldu.tistory.com/336 https://jojoldu.tistory.com/339 https://docs.spring.io/spring-batch/reference/readersAndWriters.html